¿Con qué trabajo en un SIG?
Introducción
De todos los subsistemas de SIG, el correspondiente a los datos es el pilar fundamental que pone en marcha los restantes. Los datos son el combustible que alimenta a los restantes subsistemas, y sin los cuales un SIG carece por completo de sentido y utilidad.
El subsistema de datos es, a su vez, el más interrelacionado, y está conectado de forma inseparable a todos los restantes. Mientras que, por ejemplo, la visualización no es imprescindible para el desarrollo de procesos de análisis, no hay elemento del sistema SIG que pueda vivir si no es alimentado por datos. Los datos son necesarios para la visualización, para el análisis y para dar sentido a la tecnología y, en lo referente al factor organizativo y a las personas, el rol de estas en el sistema SIG es en gran medida gestionar esos datos y tratar de sacar de ellos el mayor provecho posible. Por tanto, los datos son fundamentales en un SIG, y todo esfuerzo dedicado a su estudio y a su mejor manejo será siempre positivo dentro de cualquier trabajo con SIG.
La forma en que los datos se gestionan en un SIG es un elemento vital para definir la propia naturaleza de este, así como sus prestaciones, limitaciones y características generales.
Datos vs Información
} Existe una importante diferencia entre los conceptos de datos e información . Ambos términos aparecen con frecuencia y pueden confundirse, pese a que representan cosas bien diferentes. Un SIG es un Sistema de Información Geográfica, pero maneja datos geográficos, existiendo diferencias entre estos conceptos.
Entendemos como dato al simple conjunto de valores o elementos que utilizamos para representar algo. Por ejemplo, el código 502132N es un dato. Este código por sí mismo no tiene un significado, y es necesario interpretarlo para que surja ese significado. Al realizar esa interpretación, el dato nos informa del significado que tiene, y es en ese momento cuando podemos emplearlo para algún fin y llevar a cabo operaciones sobre él que tengan sentido y resulten coherentes con el significado propio que contiene.
El dato anterior podemos interpretarlo como si fuera una referencia geográfica, y cuyo significado sería entonces una latitud, en particular 50° $21'$ $32''$ Norte. Si lo interpretamos como un código que hace referencia a un documento de identificación de una persona, la información que nos aporta es en ese caso completamente distinta. El dato sería el mismo, formado por seis dígitos y una letra, pero la información que da es diferente, ya que lo entendemos e interpretamos de manera distinta.
La información es, por tanto, el resultado de un dato y una interpretación, y el trabajo con datos es en muchos casos un proceso enfocado a obtener de estos toda la información posible. Un dato puede esconder más información que la que a primera vista puede apreciarse, y es a través de la interpretación de los datos como se obtiene esta.
En el capítulo Geomorfometria veremos cómo a partir de un Modelo Digital de Elevaciones podemos calcular parámetros tales como la pendiente, extraer el trazado de la red de drenaje o delimitar las subcuencas en que una cuenca vertiente mayor puede dividirse. El dato en este caso lo constituyen los valores que representan la elevación en los distintos puntos. La información que contienen está formada por todo ese conjunto de elementos que podemos obtener, desde la pendiente a los cursos de los ríos, pasando por todo aquello que mediante la aplicación de procesos u operaciones de análisis podamos extraer de esos datos.
Comprender el significado y las diferencias entre datos e información permiten entender, entre otras cosas, que la relación entre los volúmenes de ambos no es necesariamente constante. Por ejemplo, los datos 502132NORTE o CINCUENTA VEINTIUNO TREINTAYDOS NORTE son mayores en volumen que 502132N, pero recogen la misma información espacial que este (suponiendo que los interpretamos como datos de latitud). Tenemos más datos, pero no más información. Podemos establecer planteamientos basados en este hecho que nos ayuden a almacenar nuestra información geográfica con un volumen de datos menor, lo cual resulta ventajoso. Veremos algunos de estos planteamientos más adelante dentro de esta parte del libro.
Aspectos como estos son realmente mucho más complejos, y el estudio de la relación entre datos e información y sus características no es en absoluto sencilla. Existe una disciplina, la ciencia de la información , dedicada a estudiar los aspectos teóricos relativos a la información y la forma en que esta puede contenerse en los datos. El lector interesado puede consultar [ Diener1989ASIS ][ Williams1997InfoScience ] para saber más al respecto.
En este capítulo de introducción a la parte dedicada a los datos, veremos más acerca de la información que de los datos espaciales, pues la manera en que concebimos esta condiciona la forma de los datos. Será en el capítulo siguiente cuando tratemos ya los datos, abordando uno de los problemas fundamentales: la creación del dato espacial.
Las componentes de la información geográfica
Comprender la información geográfica es vital para poder capturar dicha información e incorporarla a un SIG. En líneas generales, podemos dividir esta en dos componentes principales, cada una de los cuales tiene su implicación particular en los procesos posteriores de representación que más adelante veremos.
- Componente espacial
- Componente temática
La componente espacial hace referencia a la posición dentro de un sistema de referencia establecido. Esta componente es la que hace que la información pueda calificarse como geográfica , ya que sin ella no se tiene una localización, y por tanto el marco geográfico no existe. La componente espacial responde a la pregunta ¿dónde?
Por su parte, la componente temática responde a la pregunta ¿qué? y va invariablemente unida a la anterior. En la localización establecida por la componente espacial, tiene lugar algún proceso o aparece algún fenómeno dado. La naturaleza de dicho fenómeno y sus características particulares quedan establecidas por la componente temática.
Puede entenderse lo anterior como una variable fundamental (la componente temática), que se sirve de una variable soporte (la componente espacial) para completar su significado.
Los tipos de división horizontal y vertical de la información que veremos más adelante implican una separación en unidades, que en la práctica puede implicar en un SIG que cada una de esas unidades quede almacenada en un lugar o fichero distinto. En el caso de las componentes temática y espacial de la información, son posibles distintos enfoques, ya que estas pueden almacenarse de forma conjunta o bien por separado. El capitulo Bases_datos trata estos enfoques, y en él veremos con detalle cómo puede abordarse el almacenamiento de ambas componentes de la mejor forma posible, así como la evolución que se ha seguido al respecto dentro del campo de los SIG.
Mientras que la componente espacial va a ser generalmente un valor numérico, pues son de esa naturaleza los sistemas de coordenadas que permiten expresar una posición concreta en referencia a un marco dado, la componente temática puede ser de distintos tipos:
-
Numérica
. A su vez, pueden señalarse los siguientes grupos:
- Nominal . El valor numérico representa una identificación. Por ejemplo, el número de un portal en una calle, o el numero del DNI de una persona. Este tipo de variable, al igual que la de tipo alfanumérico, es de tipo cualitativo, frente a las restantes que son de tipo cuantitativo.
- Ordinal . El valor numérico establece un orden. Por ejemplo, una variable que recoja el año de fundación de una serie de ciudades.
- Intervalos . Las diferencias entre valores de la variable tienen un significado. Por ejemplo, entre dos valores de elevación.
- Razones . Las razones entre valores de la variable tienen un significado. Por ejemplo, podemos decir que una precipitación media de 1000mm es el doble que una de 500mm. La pertenencia de una variable a un grupo u otro no solo depende de la propia naturaleza de la misma, sino también del sistema en que se mida. Así, una temperatura en grados centígrados no se encuentra dentro de este grupo (pero sí en el de intervalos), ya que la razón entre dichas temperaturas no vale para decir, por ejemplo, que una zona está al doble de temperatura que otra, mientras que si expresamos la variable temperatura en grados Kelvin sí que podemos realizar tales afirmaciones. El valor mínimo de la escala debe ser cero.
- Alfanumérica
El tipo de variable condiciona las operaciones que pueden realizarse con un dato geográfico en función de cómo sea su componente temática. Por ejemplo, carece sentido realizar operaciones aritméticas con variables de tipo ordinal o nominal, mientras que es perfectamente lógico con los restantes tipos dentro de la categoría numérica. También, como veremos en el capítulo El_Mapa , influye en la forma de representarlo a la hora de elaborar cartografía.
Además de las componentes espacial y temática, Sinton [ Sinton1978Addison ] añade la componente temporal y propone un esquema sistemático que permite clasificar en grupos las distintas clases de información geográfica. Según este esquema, cada una de estas componentes puede estar en uno de los siguientes tres estados posibles: fija, controlada o medida . Al medir una de estas componentes, es necesario controlar otra de ellas, y fijar la tercera, o bien ignorarla y no tenerla en cuenta (este era el caso explicado hasta el momento, en el cual no habíamos citado aún la componente temporal)
Por ejemplo, si registramos la temperatura a lo largo de un periodo de tiempo para un punto concreto, la componente temporal está controlada (tomamos mediciones de temperatura con un intervalo de tiempo establecido), la componente temática (la propia temperatura) está medida, y la componente espacial está fija (el termómetro que registra los valores se encuentra siempre en un punto inmóvil)
En general, la información geográfica se recoge haciendo fija la componente temporal, y midiendo o controlando las restantes en función del tipo de información de que se trate.
Un concepto a tener en cuenta en relación con las componentes de la información geográfica es la dimensión . Los elementos que registramos pueden ir desde sencillos puntos (0D) hasta volúmenes tridimensionales (3D). Un caso particular —y muy frecuente— lo encontramos cuando estudiamos la forma tridimensional del terreno, pero tratando la elevación como variable temática, no como una parte más de la componente espacial. En este caso, tenemos una serie de valores de elevación (Z) localizados en el plano XY. Esto no es realmente equivalente a utilizar una componente espacial tridimensional, ya que no permite recoger en un mismo punto distintos valores (no puede, por ejemplo, modelizarse la forma de una cueva o un objeto vertical), por lo que se conoce como representación en 2.5 dimensiones (2.5D). La figura \ref{Fig:Dimensiones} muestra esquemáticamente el concepto de dimensión de los datos dentro de un SIG.

Por ultimo, un aspecto importante de toda variable estudiada es su continuidad . Se entiende esta continuidad como la capacidad de la variable para tomar todos los valores dentro de un rango definido. La temperatura, la presión o la elevación son valores continuos, mientras que ninguna variable de tipo nominal puede ser continua, ya que se encuentra limitada a un numero (finito) de identificadores posibles. Por ejemplo, en el caso del número de un DNI, los valores son siempre enteros, existe el valor 1 y el valor 2, pero no los infinitos valores decimales entre ambos.
La continuidad de la variable temática se puede estudiar igualmente en relación con la componente espacial. Así, existen variables que varían de forma continua en el espacio, mientras que otras no lo hacen. Se emplea aquí el concepto matemático de continuidad, es decir, que si trazáramos un perfil de la variable a lo largo de un recorrido dado, la representación de dicho perfil sería una curva que podría dibujarse sin levantar el lápiz del papel.
Todas estas ideas referidas a las distintas variables (distintas informaciones que pretendemos recoger de una zona de estudio dada) nos servirán para detallar los diferentes enfoques de representación y almacenamiento que veremos en el próximo capítulo, y escoger en cada caso el más apropiado.
División horizontal de la información geográfica
Además de dividir la información geográfica en componentes, también dividimos esta con criterios puramente espaciales, «cortándola» en unidades menores que ocupen una región de amplitud más reducida. Este es un procedimiento similar al que encontramos en un mapa impreso, ya que el territorio de un país se encuentra cartografiado en diferentes hojas . Las razones para esto son, por una parte, los posibles distintos orígenes que los diferentes mapas pueden tener (cada región puede ser responsable de fabricar los suyos) y, especialmente, el hecho de que, de no ser así, los mapas tendrían un tamaño inmanejable. Si cartografiamos a escala 1:25000 todo un país, es obvio que no podemos hacerlo en un único mapa, ya que este sería enorme.
En el caso de trabajar en un SIG, no tenemos el problema del tamaño físico del mapa, ya que no existe tal tamaño. Los datos no ocupan un espacio físico, pero sí que requieren un volumen de almacenamiento, y este presenta el mismo problema. Recoger a escala 1:25000 todo un país supone un volumen de datos enorme, que es conveniente dividir para poder manejar con fluidez.
En ambos casos, ya sea dentro de un SIG o no, suele resultar necesario emplear varios bloques de información (varias hojas) para cubrir un área de trabajo. En esta circunstancia, las propias características de un SIG y su forma de trabajo con los datos hacen que este proceso sea más sencillo y eficaz.
La principal cualidad de un SIG para integrar de forma transparente datos correspondientes a zonas distintas y formar un mosaico único es la separación que existe entre datos y visualización. Los datos son la base de la visualización, pero en un SIG estos elementos conforman partes del sistema bien diferenciadas. Esto quiere decir que los datos se emplean para crear un resultado visual pero en sí mismos no contienen valores relativos a esa visualización.
De este modo, es posible combinar los datos y después representarlos en su conjunto. Un proceso así no puede realizarse con un mapa ya impreso, pues este contiene ya elementos de visualización e incluso componentes cartográficos tales como una flecha indicando el Norte, una leyenda o una escala. Por ello, aunque puedan combinarse, realmente no se «funde» la información de cada uno de los mapas para conformar uno único. Dicho de otro modo, si tomamos cuatro hojas contiguas de una serie de mapas no podemos formar un nuevo mapa que sea indistinguible de uno cuatro veces más grande que haya sido impreso en un único pliego de papel.
En un SIG, sin embargo, sí que sucede así, y la visualización de cuatro o más bloques de datos puede ser idéntica a la que obtendría si todos esos datos constituyeran un único bloque. Empleando herramientas habituales en un SIG, y si cada uno de esos bloques está almacenado en un fichero, resulta incluso posible unirlos todos y crear un solo fichero que los contenga.
Una de las razones principales que favorecen esta combinación de datos es el hecho de que la escala nominal es en sí un elemento de representación. Como vimos en el apartado Escala , la escala nominal relaciona el tamaño que tiene un objeto en la representación con su tamaño real, y la forma en que se recoge la información a la hora de realizar medidas de ese objeto viene condicionada por dicha escala, de tal modo que el esfuerzo desarrollado en esas mediciones sea coherente con la representación que se va a hacer posteriormente al crear el mapa.
Los datos que manejamos en un SIG tiene una escala de detalle impuesta por la precisión de las mediciones, pero no una escala nominal asignada, ya que no tienen un tamaño fijo de representación en la pantalla del ordenador o el periférico correspondiente, al contrario que un mapa impreso en el que los distintos elementos ya se encuentran representados. Esto hace que combinar cartografía clásica a distintas escalas sea complejo, ya que los mapas no «casan» bien entre sí.
En el caso de un SIG, es el usuario el que decide la escala de representación, y esta será la misma para todos los datos que se visualicen, independientemente de las características de estos. En el contexto actual de datos geográficos, es habitual encontrar situaciones en las que para una zona de terreno disponemos de información a una escala, y para otra zona contigua a esta la información disponible es a una escala distinta. Con el uso de un SIG, sin embargo, es posible trabajar sin problemas con todo el conjunto, sin preocuparse por la integración de sus distintas partes.
Lógicamente, no debe dejarse de lado nunca el rigor cartográfico y, como se dijo en su momento, no olvidar que, aunque podamos representar cualquiera de esos datos a la escala que deseemos, los datos en sí no son suficientes para ello y tienen unas limitaciones impuestas por su escala inherente. Es decir, que no es necesario preocuparse por la integración a la ahora de visualizar y gestionar los datos, pero sí a la hora de analizarlos u obtener resultados a partir de ellos. No obstante, el proceso de combinación es en cualquier caso transparente para el usuario que visualiza esos datos en un SIG, y la operación pasa de ser algo tedioso y complejo a algo prácticamente inapreciable dentro del SIG, pues es este quien se encarga de ocultar toda esa complejidad y simplemente generar las representaciones según los parámetros requeridos en cada momento.
La figura \ref{Fig:Distintas_escalas_horizontal} muestra un ejemplo de lo anterior en el que puede verse cómo varias fotografías aéreas forman un mosaico que cubre una zona dada, teniendo estas distinto nivel de detalle.

División vertical de la información. Capas
Uno de los grandes éxitos de los SIG es su estructura de manejo de información geográfica, que facilita todas las operaciones que se llevan a cabo con esta. El concepto de capa , imprescindible para comprender todo SIG, es una de las grandes virtudes inherentes a los Sistemas de Información Geográfica, ya que favorece la correcta estructuración de la información y el trabajo con ella.
La división horizontal que ya hemos visto no es algo nuevo, y la gran mayoría de los mapas clásicos cubren una porción relativamente pequeña de la superficie terrestre. Combinando distintos mapas podemos formar uno mayor que cubra una extensión más amplia, y aunque ya hemos visto que esto mismo puede realizarse con un SIG y la tarea resulta así más sencilla, no resulta una operación tan compleja y extraña en el caso de no trabajar en un entorno SIG.
Más difícil, sin embargo, es combinar distintos tipos de información, como por ejemplo la contenida en un mapa topográfico y la existente en un mapa de tipos de suelo y otro de vegetación potencial. Para una misma zona, trabajaremos con varios mapas simultáneamente, y combinar estos para la realización de operaciones en las que intervengan todos ellos(supongamos, por ejemplo, calcular el área total de las zonas con un tipo de suelo dado donde la vegetación corresponde a una clase concreta y se encuentran por encima de 1000 metros) es difícil y generalmente también impreciso.
En el caso de un SIG, los distintos tipos de información se pueden combinar de forma sencilla y limpia, y no aparecen los mismos problemas. Esto es así debido a que la idea de capa permite dividir la información espacial referida a una zona de estudio en varios niveles, de tal forma que, pese a coincidir sobre un mismo emplazamiento, información sobre distintas variables se encuentra recogida de forma independiente. Es decir, en función de la componente temática se establecen distintos bloques de datos espaciales.
Para comprender mejor el concepto de capa, pensemos en un mapa topográfico clásico. En él vamos a encontrar elementos como curvas de nivel, carreteras, núcleos urbanos, o simbología relativa a edificios y puntos singulares (iglesias, monumentos, etc.) Todos estos elementos en su conjunto componen el mapa, y aparecen en una misma hoja como una unidad coherente de información geográfica. No obstante, cada uno de los de estos grupos de información recogidos —elevaciones, red viaria, núcleos urbanos, puntos de interés arquitectónico— pueden recogerse de forma independiente, y combinarse al componer el mapa según las necesidades del momento, o bien combinarse de modo distinto o emplearse individualmente (Figura \ref{Fig:Concepto_capa}).
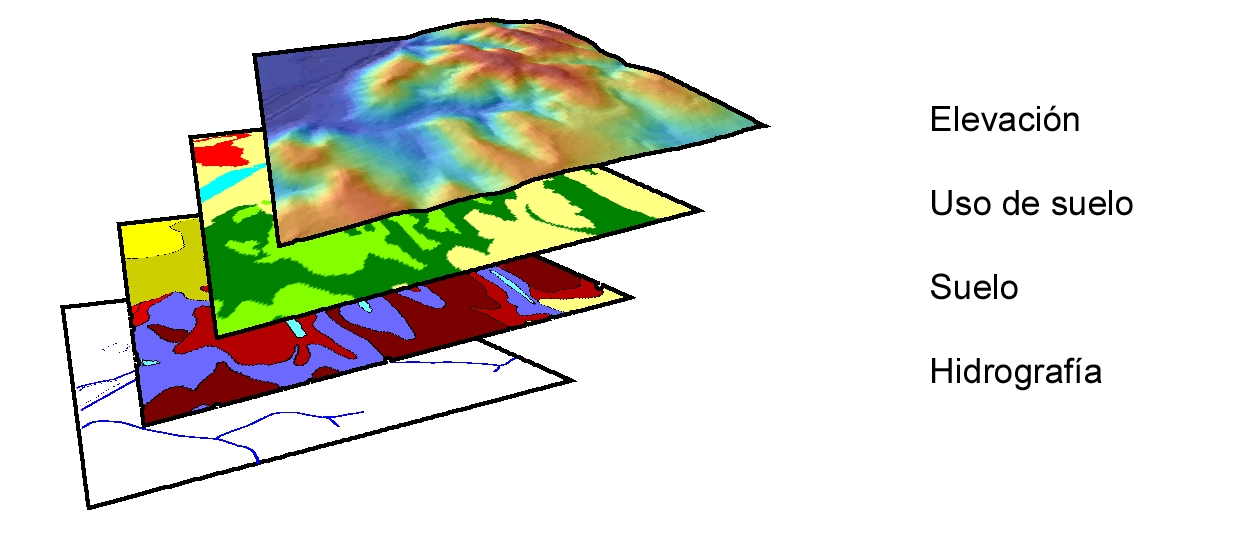
La figura es lo suficientemente gráfica como para entender la razón de que a este tipo de división la denominemos vertical , así como el propio nombre de capa , ya que de ella resulta una serie de diferentes niveles que se pueden superponer según el criterio particular de cada usuario de SIG.
Toda la información geográfica con que trabajemos en un SIG va a ser en forma de capas. Cada una de estas capas puede abrirse de forma independiente en un SIG y utilizarse por sí misma o en conjunto con otras en la combinación que se desee.
Esta forma de proceder no es exclusiva de los SIG, y antes de la aparición de estos ya existían experiencias previas en este sentido, combinándose capas de información geográfica para la realización de análisis (véase Evolucion_tecnicas ). Es, sin embargo, con la aparición de los SIG cuando esta metodología se aplica de forma regular y se establece sistemáticamente dicha estructuración de la información geográfica.
Así, la visualización, el análisis, y todas las acciones que se realizan sobre la información geográfica dentro de un SIG, se llevan a cabo sobre un conjunto de capas, entendiéndose cada una de ellas como la unidad fundamental de información sobre una zona dada y un tipo de información concreta.
La relevancia del concepto de capa como elemento fundamental de un SIG es enorme, pues realmente constituye el marco básico sobre el que se van a llevar a cabo gran parte de las operaciones. Algunas de las posibilidades que brinda esta filosofía ya las conocemos. Por ejemplo, vimos en el apartado dedicado a la generalización cartográfica cómo en un SIG podemos utilizar diferentes «versiones» de los datos correspondientes a una zona concreta, y representar una u otra de ellas en función de la escala de trabajo. Para un tipo de información, por ejemplo los usos del suelo, estas versiones se almacenarán como distintas capas. La capa es así la unidad fundamental no solo en términos de un área dada, sino también de una escala concreta, y permite una división de los datos óptima a todos los efectos.
Al igual que veíamos en el apartado anterior, las capas nos van a permitir la combinación de datos a distinta escala, no ya en este caso datos contiguos, sino datos correspondientes a un mismo área pero con variables distintas. Esto es de gran utilidad en el trabajo habitual, ya que no todas las variables se recogen con un mismo nivel de detalle, y el detalle con el que podemos encontrar una capa de elevaciones va a ser generalmente mucho mayor que el que cabe esperar para una capa de, digamos, litología.
En realidad, y en el lenguaje habitual de trabajo con SIG, la capa no define únicamente una división vertical, sino también una horizontal. Es más sencillo visualizar la idea de capa con un esquema como el de la figura \ref{Fig:Concepto_capa}, en el que las distintas variables se «apilan» en capas de información superpuestas. Sin embargo, las divisiones horizontales en un mosaico de datos también se consideran como capas distintas en un SIG, pese a contener una misma variable y un mismo tipo de información. Por tanto, y aunque la división vertical sea la que verdaderamente define la idea de capa, cuando hablamos de una capa de datos en un SIG nos referimos a un «trozo» de toda la información disponible, que implica una sección en la dimensión vertical (la de las variables existentes que pueden estudiarse) y un recorte en la horizontal (la de la superficie geográfica).
Las capas pueden emplearse también para incorporar en cierta forma la variable temporal si se considera que la dimensión vertical es el tiempo. Aunque no es la manera más adecuada, y en la actualidad el manejo del tiempo es uno de los principales problemas a resolver en el diseño de los SIG, podemos trabajar con varias capas que representen una misma información y una misma zona, pero en instantes distintos. Esto no es distinto a trabajar con mapas clásicos correspondientes a diferentes instantes, salvo que en el caso de capas cada elemento de la información se encuentra separado a su vez.
Por último, es importante el hecho de que la separación de la información en capas evita la redundancia de datos, ya que cada capa contiene un tipo de información concreto. En un mapa clásico se presentan siempre varias variables, algunas de ellas presentes con carácter general, tales como nombres de ciudades principales o vías más importantes de comunicación. Es decir, que un mapa de usos de suelo o un mapa geológico van a contener otras variables, que en ocasiones se añaden a este para enriquecerlo. Unas curvas de nivel, por ejemplo, permitirán una mejor interpretación de esa geología.
Al dividir toda la información en capas, podemos combinar curvas de nivel y geología, añadir otros elementos, o bien representarlas de forma aislada, algo que no resulta posible si los datos de los que disponemos ya vienen unidos inseparablemente, como sucede en el caso de la cartografía impresa. La división en capas ofrece un mayor número de posibilidades distintas de trabajo y, como iremos viendo a lo largo de gran parte de este libro, también mayores posibilidades de análisis y proceso.
En resumen, el trabajo con capas permite una estructura más organizada y una mayor atomización de los datos, con las consecuentes ventajas en el almacenamiento, manejo y funcionalidad que esto conlleva.
Resumen
Los datos son una de las piezas más importantes del sistema SIG. Entendemos por dato un conjunto de valores o elementos que representan algo. La interpretación correcta de esos datos los dota de significado y produce información .
La información geográfica tiene dos componentes: una componente temática y una componente geográfica. Estas van unidas y conforman una unidad única de información geográfica, aunque pueden separarse y analizarse por separado. Mientras que la componente geográfica tiene un carácter fundamentalmente numérico, la componente temática puede incluir una o varias variables y estas ser de naturaleza muy variada.
La información geográfica se divide horizontal y verticalmente. Las unidades mediante las que incorporamos esta información a un SIG se conocen como capas , y son uno de los elementos primordiales en la estructura de manejo de datos de todo SIG. El trabajo con capas hace más transparente la gestión de la información geográfica en un SIG, permite una mejor integración de distintos datos, y es la base para muchas operaciones, algunas de las cuales iremos viendo en capítulos sucesivos.