Consultas y operaciones con bases de datos
Introducción
El análisis más simple que podemos efectuar sobre una capa (o varias) de información geográfica es la simple consulta de esta. Entendemos por consulta una operación en la cual preguntamos a los datos geográficos algún tipo de cuestión simple, generalmente basada en conceptos formales sencillos. Este tipo de análisis, aunque no implica el uso de conceptos analíticos complejos, es uno de los elementos clave de los SIG, pues es parte básica del empleo diario de estos.
En el contexto espacial, una consulta representa un uso similar al que damos a un mapa clásico, cuando en base a este respondemos a preguntas como ¿qué hay en la localización X? o ¿qué ríos pasan por la provincia Y? No obstante, no debemos olvidar que los datos espaciales tienen dos componentes: una espacial y otra temática. Preguntas como las anteriores hacen referencia a la componente espacial, pero igualmente pueden efectuarse consultas que se apliquen sobre la parte temática. Y más aún, pueden efectuarse consultas conjuntas que interroguen a los datos geográficos acerca de los atributos espaciales y temáticos que estos contienen.
Las consultas se entienden en general como relativas a capas vectoriales, pues son dicho modelo de representación y su estructura de datos los que mejor se adaptan a la forma particular de las consultas. En este capítulo veremos cómo trabajar mayoritariamente con datos vectoriales, aunque también se harán referencias a datos ráster, ya que estos últimos contienen igualmente datos geográficos y pueden consultarse y responder a preguntas como las formuladas anteriormente.
En las capas vectoriales, y como vimos en los capítulos Tipos_datos y Bases_datos , la división entre la componente temática y espacial es más patente, existiendo incluso una división a nivel de archivos y de los elementos tecnológicos empleados para el trabajo con cada una de ellas dentro de un SIG. En el caso de las consultas, se mantiene un enfoque similar, y encontramos esa misma separación. Los lenguajes de consulta, que en breve veremos con más detalle y que resultan básicos para elaborar consultas y obtener resultados, han seguido una evolución paralela a la de los propios sistemas gestores de bases de datos en su adaptación al entorno espacial de los SIG.
Siguiendo este mismo enfoque, estudiaremos en primer lugar los conceptos fundamentales relativos a consultas en bases de datos, sin tratar por el momento la componente espacial. Posteriormente extenderemos estos conceptos para ver la verdadera potencia de estas dentro del ámbito SIG, que resulta de añadir la componente espacial y los conceptos sobre relaciones espaciales que vimos en el capítulo Analisis_espacial .
Si estás familiarizado con los conceptos relativos a bases de datos no espaciales y las consultas sobre estas, puedes prescindir de leer la próxima sección y avanzar hasta la siguiente para ver directamente las particularidades del trabajo con bases de datos espaciales. De cualquier modo, el capítulo no pretende ser un manual sobre el uso de bases de datos o sus fundamentos, ya que es un tema muy amplio y escapa por completo al alcance de este texto.
Consultas en un SIG
Si partimos de datos vectoriales y de la presencia de algún sistema gestor de bases de datos o tecnología similar dentro de un SIG, una consulta no es sino una llamada a dicho sistema gestor, el cual devuelve como respuesta una serie de elementos tomados de la información contenida en la base de datos. Es decir, del total de datos obtenemos como consecuencia de la consulta una parte de los mismos. La respuesta a nuestra consulta es un conjunto de elementos, de la misma forma que si en un mapa impreso preguntamos ¿qué hay aquí? y obtenemos como respuesta los datos correspondientes al punto que señalamos. Estos datos son una fracción particular del conjunto de todos los contenidos en dicho mapa.
El resultado de una consulta en un SIG generalmente es lo que conocemos como selección . De todos los registros de la tabla de datos, aquellos que cumplen el criterio indicado se marcan como seleccionados, y posteriormente pueden utilizarse únicamente estos como base de otro análisis, o simplemente el usuario puede ver cuáles han sido los seleccionados para así obtener la respuesta a su consulta.
Como veremos más en detalle en las siguientes secciones, las consultas pueden hacerse sobre la componente temática de los datos, sobre la espacial, o sobre ambas. En cualquier caso, sabemos ya que estas en un SIG se encuentran vinculadas, con lo que el resultado de la consulta afecta a ambas. La selección se hace patente sobre ambas componentes, con independencia de cuál de ellas haya sido la encargada de aplicar el criterio de selección. En el entorno habitual de un SIG, con su interfaz gráfica, tanto la tabla de atributos como la representación visual de la componente espacial se ven afectadas por la realización de una consulta. La figura \ref{Fig:Seleccion} muestra gráficamente este hecho.
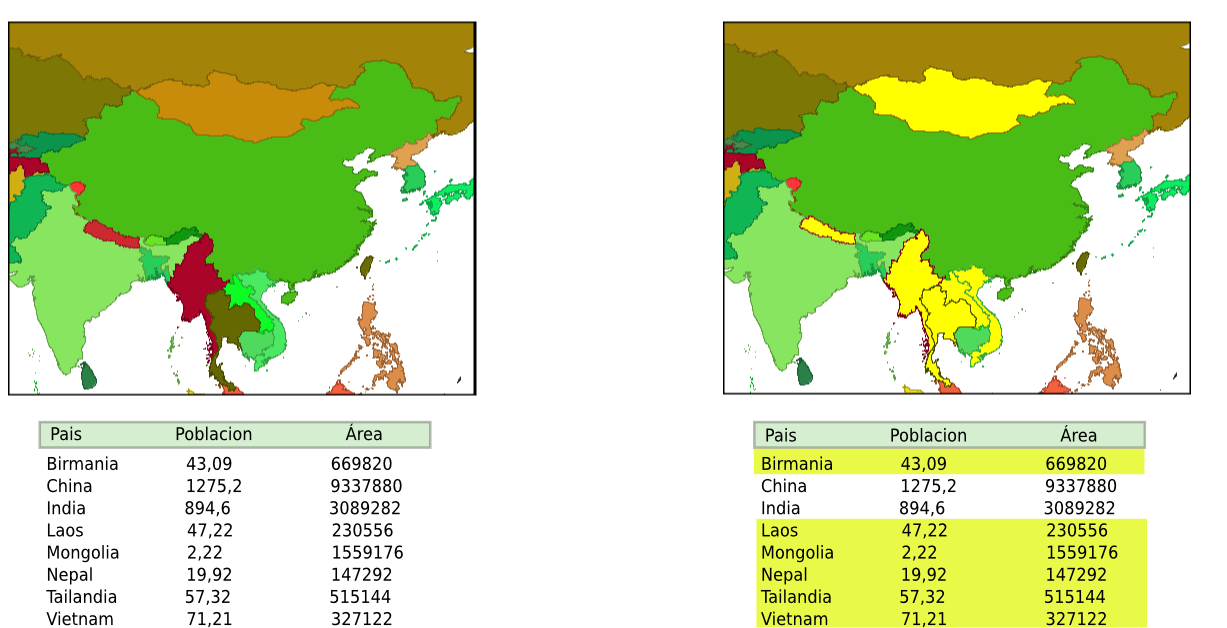
Esta presencia gráfica es importante dentro del entorno de los SIG, tanto para mostrar el resultado de las consultas como para ayudar en la formulación de estas. En contraste con el carácter textual de una base de datos, el empleo de dichas bases de datos y la realización de consultas en un SIG incorpora una representación gráfica que resulta esencial [ Guting1994VLDB ]
Junto con la selección de entidades dentro de una capa existente, una consulta nos vale también para extraer información de una base de datos de acuerdo a nuestras necesidades, y para crear posteriormente y a partir de dicha información una nueva capa. Esta operación es útil cuando la base de datos de la que disponemos es muy voluminosa y solo resulta de interés para nuestro trabajo una parte de ella. Puede tratarse de una parte en el sentido espacial (la base de datos contiene datos a nivel mundial y se quiere trabajar a nivel estatal), en el sentido temático (la base de datos contiene mucha información de cada entidad y solo interesan algunos campos), o en una combinación de ambas. Para extraer dicha parte y trabajar únicamente con ella, utilizaremos una consulta.
Así, la selección de una serie de entidades dentro de una capa o la extracción de dichas entidades de la base de datos para la creación de dicha capa son dos aplicaciones habituales de las consultas que seguidamente veremos.
Consultas temáticas
Comencemos analizando algunas consultas temáticas y viendo cómo, aunque se realicen en base a datos espaciales como los que utilizamos en un SIG, en realidad en ellas la componente espacial no se emplea. Sea por ejemplo una capa con los distintos países del mundo y una serie de valores económicos y sociales asociados a cada uno de ellos. Consideremos las siguientes preguntas:
- ¿Qué países tienen un Producto Interior Bruto mayor que el de España?
- ¿Qué países han experimentado un crecimiento económico en el último año?
- ¿Cuántos países tienen más de 200 millones de habitantes?
En todos estos casos estamos haciendo referencia a países, los cuales, como sabemos, estarán asociados a elementos geométricos que definan sus propiedades espaciales, es decir, a una componente espacial. Esta componente es la que permite que, además de poder plantear las consultas anteriores, podamos representar cada país en la pantalla y visualizarlo, o saber cuáles de ellos se encuentran en el hemisferio norte (esta sería una consulta espacial, de las que más adelante en este mismo capítulo veremos).
Sin embargo, cuando realizamos consultas como las tres anteriores, no acudimos a la componente espacial. Consultas como estas podrían resolverse si en lugar de una capa dentro de un SIG tuviéramos, por ejemplo, un simple anuario estadístico lleno de tablas con datos correspondientes a cada país. De hecho, antes del desarrollo de los SIG, ese tipo de datos, aunque referidos a elementos geográficos, se almacenaban en documentos tales como dicho anuario, y no específicamente en mapas. Es fácil encontrar mapas del mundo con meras divisiones fronterizas entre países (un mapa político) o quizás con elevaciones y elementos orográficos (un mapa físico), pero no es tan sencillo adquirir un mapa en el que pueda conocerse el crecimiento económico del ultimo año en cada país. Esta información se puede adquirir, sin embargo, de forma sencilla en ese anuario estadístico que citamos.
Antes de la aparición de los SIG, la componente temática (el anuario estadístico) y la espacial (el mapa político) iban por separado. Hoy en día, y gracias a los SIG, podemos trabajar con ellas de forma conjunta, pues es fácil ver que existe una relación entre ambas.
Por un momento, dejemos de lado la componente espacial de cada país, y pensemos que solo conocemos de él algunas variables socio--económicas tales como el PIB, la población, el idioma que se habla o el nombre de su moneda, tal y como se recogen en la tabla de la figura \ref{Fig:Seleccion}
Mecanismos de consulta y operaciones básicas
Consultas como las anteriores pueden expresarse fácilmente en un idioma tal como el español y son de igual modo fácilmente entendibles por cualquiera que conozca este idioma. El problema es que el ordenador, y por tanto el Sistema de Información Geográfica, no entiende estas expresiones, siendo necesario formular las consultas de alguna forma que pueda ser interpretada correctamente por el SIG o el gestor de bases de datos correspondiente.
Dentro de un SIG hay muchas formas de expresar una consulta. Una forma simple es a través de expresiones lógicas relativas a los campos de la tabla de atributos. Planteando las consultas como expresiones condicionales, la respuesta a estas son aquellas entidades que hacen verdadera dicha expresión.
Para trabajar desde este punto en adelante, vamos a suponer que disponemos de una tabla con datos de países del mundo, la cual contiene los siguientes campos:
- NOMBRE
- CAPITAL
- MONEDA
- POBLACION_ACTUAL
- POBLACION_ANTERIOR
- SUPERFICIE
Por ejemplo, para saber el número de países con población mayor de 200 millones, podríamos utilizar una expresión como la siguiente: 'POBLACION_ACTUAL' $>$ 200000000. Para saber en qué países aumentó la población en el ultimo año, y puesto que disponemos además de un campo con la población de año anterior, podemos plantear una expresión de la forma POBLACION_ACTUAL > POBLACION_ANTERIOR .
Estas expresiones condicionales se conocen con el nombre de predicados .
Los predicados no han de ser necesariamente de carácter numérico. Por ejemplo, para saber qué países pertenecen a la Unión Económica Europea podríamos hacerlo mediante el predicado MONEDA = 'Euro' .
Consultas de esta índole también pueden efectuarse si los datos geográficos se basan en un modelo de datos ráster. En este caso, podemos de igual modo ver qué celdas cumplen una condición dada como, por ejemplo, tener un valor mayor que un valor predefinido. Sin embargo, este tipo de operaciones no se suelen ver habitualmente como consultas, sino como operaciones de lo que se conoce como álgebra de mapas , en particular una operación denominada reclasificación . Veremos con detalle estas operaciones en el capitulo Algebra_de_mapas , enteramente dedicado a ellas.
Las consultas mediante expresiones condicionales pueden ser algo más complejas que lo que hemos visto hasta ahora, ya que pueden hacer referencia a varios campos. Por ejemplo, para responder a cuestiones como las siguientes:
- ¿Qué países de la zona euro tienen más de 40 millones de habitantes?
- ¿En qué países de habla inglesa aumentó la población durante el último año?
Para expresar esas consultas se han de incluir elementos de la denominada lógica booleana . Para entender de forma sencilla este concepto, podemos reescribir las consultas anteriores de la siguiente manera:
- ¿Qué países tienen como moneda el euro y tienen más de 40 millones de habitantes?
- ¿Que países hablan inglés y experimentaron un aumento de población durante el último año?
La partícula y nos indica que realmente nuestra consulta se compone de dos condiciones. Por ejemplo, en el primero de los casos se debe cumplir la condición Moneda = 'Euro' , y al mismo tiempo la condición POBLACION_ACTUAL $>$ 40000000. La sintaxis habitual para expresar esto a la hora de formular la consulta es emplear el termino inglés AND , de forma que tendríamos la expresión MONEDA = 'Euro' AND POBLACION_ACTUAL $>$ 40000000 .
Otros operadores lógicos que podemos emplear son el operador disyuntivo o ( OR ) o el operador de negación ( NOT ). Añadiéndolos a las expresiones condicionales podemos crear consultas más elaboradas para extraer la información que buscamos.
En realidad, formular una consulta de este tipo es buscar un subconjunto particular (el formado por las entidades que quedarán seleccionadas) dentro de un conjunto global (la capa geográfica). Por ello, es útil plantear estas operaciones lógicas desde el punto de vista de la teoría de conjuntos, y hacer uso de los denominados diagramas de Venn , que muestran de forma gráfica y muy intuitiva el significado de dichas operaciones. En la figura \ref{Fig:Venn} pueden verse los diagramas correspondientes a las operaciones que hemos visto hasta el momento.
Más adelante volveremos a encontrar esquemas similares a estos, en particular al estudiar las operaciones de solape entre capas vectoriales, en el capítulo Operaciones_geometricas .

Una operación muy habitual en el ámbito de las bases de datos es la unión de tablas. Si la componente temática en el modelo vectorial se almacena en una tabla de atributos, es posible, mediante esta operación, almacenar dicha componente en un conjunto de ellas interrelacionadas, lo cual en términos generales conlleva una mejor estructuración, como ya vimos en el capítulo dedicado a las bases de datos. En otras palabras, resulta conveniente no poner toda la información en una tabla, sino dividirla en un conjunto adecuadamente estructurado de tablas, que después pueden combinarse y utilizarse de la manera que resulte más apropiada.
Lógicamente, si la información se encuentra disponible en una serie de tablas, pero las entidades geométricas que contienen la componente espacial del dato solo tienen asociada una de ellas, es necesario algún elemento adicional que permita relacionar a todas esas tablas. Este elemento son las operaciones de unión, que pueden efectuarse entre varias capas (cada una aporta su tabla de atributos) o también con tablas aisladas, sin necesidad de que estas tengan asociada una componente espacial.
Veamos un ejemplo de una unión entre tablas para comprender el significado de esta operación. En el cuadro \ref{Tabla:Tablas_base_union} se muestran dos tablas. En la primera de ellas, que supondremos que se encuentra asociada a una capa de polígonos, encontramos un valor numérico que identifica cada entidad ( ID ) y es distinto para cada una de ellas, y otro valor numérico también entero ( TIPO_SUELO ) que nos indica el grupo de tipo de suelo de dicho polígono. Es decir, es la tabla de una capa de usos de suelo. En la segunda tabla, que es una tabla no asociada a ninguna capa, encontramos la equivalencia entre los valores de tipo de suelo y el nombre de dicho tipo de suelo ( NOMBRE_SUELO ), así como en el campo denominado APTITUD , que, en una escala de 1 a 10, clasifica la aptitud del suelo para el crecimiento de una determinada especie vegetal.
| ID | TIPO_SUELO |
|---|---|
| 1 | 3 |
| 2 | 1 |
| 3 | 3 |
| 4 | 3 |
| 5 | 2 |
| TIPO_SUELO | NOMBRE_SUELO | APTITUD |
|---|---|---|
| 1 | Fluvisol | 5 |
| 2 | Cambisol | 7 |
| 3 | Leptosol | 4 |
En estas tablas existe un campo común, que es el que contiene el código numérico del tipo de suelo (en el ejemplo tiene el mismo nombre en ambas tablas, pero esto no ha de ser necesariamente así, basta con que la variable que contengan ambos campos sea la misma), y que podemos emplear para establecer la relación entre las dos tablas. Si un polígono tiene asociado un suelo de tipo 1, y gracias a la tabla adicional sabemos que el suelo de tipo 1 es un fluvisol y que su aptitud es 5, entonces podemos decir que dentro de ese polígono el suelo es de tipo fluvisol y tiene dicha aptitud, aunque en la tabla asociada no se encuentre directamente esta información. Esta forma de proceder debe resultar ya familiar, pues la unión se basa en el uso de un atributo clave, que ya vimos en el capítulo Bases_datos dedicado a las bases de datos.
Al efectuar una unión, pasamos la información de una tabla a la otra, en la medida en que esto sea coherente con las coincidencias existentes entre ellas. El resultado es una nueva tabla que extiende la tabla original, incorporando información de otra tabla adicional. En el cuadro \ref{Tabla:Resultado_union} puede verse la tabla resultante de la anterior unión.
| ID | TIPO_SUELO | NOMBRE_SUELO | APTITUD |
|---|---|---|---|
| 1 | 3 | Leptosol | 4 |
| 2 | 1 | Fluvisol | 5 |
| 3 | 3 | Leptosol | 4 |
| 4 | 3 | Leptosol | 4 |
| 5 | 2 | Cambisol | 7 |
Mantener la información dividida en varias tablas de la forma anterior tiene muchas ventajas, como ya en su momento comenzamos a ver en el apartado DisenoBaseDatos cuando tratamos el diseño de bases de datos, y ahora al estudiar las consultas vemos plasmadas de modo claro una buena parte de ellas. El hecho de codificar cada nombre de tipo de suelo con un valor numérico hace más sencillo el introducir este parámetro, pues evita teclear todo el nombre cada vez que se quiera añadir algún nuevo registro a la tabla principal (en este caso, la que se encuentra asociada a la capa). Esto además disminuye la probabilidad de que se cometan errores al introducir dichos valores y garantiza la homogeneidad de nombre, pues estos solo se encuentran almacenados una única vez en la tabla adicional. Las restantes tablas se alimentan de esta.
Las ventajas son mayores si se piensa que la tabla que caracteriza cada tipo de suelo puede estar unida no a una sola tabla de atributos, sino a un número mayor de ellas. En tal caso, ampliar o modificar la información de las tablas resulta mucho más sencillo, pues solo se deben efectuar dicha ampliación o modificación sobre la tabla de la que las demás toman sus datos. Si por ejemplo quisiéramos modificar la aptitud del tipo de suelo leptosol de 4 a 5, basta realizar esta modificación en la tabla auxiliar. El número de veces que este tipo de suelo aparece en la tabla de atributos de la capa resulta indiferente a la hora de efectuar esta modificación, pues solo ha de cambiarse una vez.
Si se desean añadir nuevos campos tales como el nombre del tipo de suelo en un idioma distinto o la aptitud de cada tipo de suelo para una especie distinta, estos no han de añadirse a cada tabla de atributos, sino solo a la tabla auxiliar. Por otra parte, el almacenamiento estructurado tiene como resultado una información menos redundante, y por tanto un menor volumen de los datos. En definitiva, existen muchas ventajas asociadas a una estructuración adecuada de los datos, las cuales pueden aprovecharse definiendo las relaciones entre todas esas tablas a través de operaciones tales como la unión.
Todas las operaciones que hemos visto se realizan de forma diferente según el SIG que empleemos, pues constituyen herramientas independientes que se implementan de una u otra forma dependiendo del producto. Existe, no obstante, una forma unificada de llamar a estas y a otras funciones, y es a través de los lenguajes de consulta . Los lenguajes de consulta son un elemento fundamental de las bases de datos y, básicamente, y como su nombre indica, se trata de lenguajes pensados para poder expresar todo tipo de consultas relativas a una base de datos y obtener así una información dada a partir de ella. Es decir, permiten expresar todas las consultas que hasta el momento hemos visto en este capítulo, así como otras más complejas y elaboradas.
En realidad, son lenguajes que buscan dar solución a todas las necesidades de trabajo con bases de datos, y estas incluyen no solo aquellas relacionadas con consultas (aunque representen la operación más habitual) sino también las que derivan del mantenimiento y creación de dicha base de datos. En su empleo más habitual, los lenguajes de consulta han de ofrecer una forma sencilla y eficaz de que un usuario cualquiera pueda efectuar consultas sobre una base de datos, formulando estas de una forma lógica y flexible.
Un lenguaje de consulta posee una sintaxis rígida, que lo asemeja a un lenguaje de programación (de hecho, se trata de un lenguaje de programación como tal). No obstante, la complejidad algorítmica inherente a la propia consulta queda oculta en la expresión, asemejándose en ese sentido más a un lenguaje natural. Un lenguaje de consulta no sirve para implementar algoritmos, sino que expresa de una forma más natural (aunque con una sintaxis adecuada al entorno computacional en que se encuentra) dichos algoritmos de consulta.
Dicho de otro modo, estos lenguajes de consulta van a expresar en líneas generales qué es lo que se quiere hacer, pero no cómo se debe hacer, al contrario que los lenguajes de programación (tales como los que se emplean para programar, por ejemplo, un SIG), que permiten describir formalmente algoritmos y procedimientos.
El siguiente paso es, pues, estudiar cómo los lenguajes de consulta se incorporan a un SIG y la forma de utilizar estos. El lenguaje de consulta más extendido para bases de datos relacionales, tanto dentro como fuera del ámbito SIG, es el denominado SQL (acrónimo de Structured Query Language o Lenguaje de Consulta Estructurado ).
El lenguaje SQL
El lenguaje SQL es un lenguaje de consulta pensado para el manejo de datos, e incluye elementos para realizar todas aquellas operaciones habituales que se presentan en el uso de una base de datos. Su utilización es habitual dentro de cualquier sistema que implique el manejo de datos mediante un gestor de bases de datos, y un cierto conocimiento de sus fundamentos es de indudable interés para el usuario de SIG. El objetivo de esta parte no es constituir una referencia de este lenguaje, sino tan solo presentar sus principales elementos para mostrar la forma en que un lenguaje de consulta soluciona las necesidades que operaciones como las vistas hasta este punto plantean dentro de un SIG. Las referencias sobre SQL son muy abundantes y el lector interesado no tendrá dificultad en encontrar docenas de libros sobre este tema. Una referencia completa es [ Beaulieu2003Anaya ].
Podemos distinguir tres componente principales dentro del SQL:
- Un lenguaje de definición de datos. Mediante él podemos definir las características fundamentales de los datos y sus relaciones.
- Un lenguaje de manipulación de datos. Permite añadir o modificar registros a las tablas de la base de datos. Las funciones de consulta también se incluyen dentro de este lenguaje
- Un lenguaje de control de datos. Sus comandos permiten controlar aspectos como el acceso a los datos por parte de los distintos usuarios, así como otras tareas administrativas
En principio, es la segunda componente —el lenguaje de manipulación de datos— la que resulta aquí de mayor interés, y a la que acudiremos de forma más frecuente, pues contiene los elementos de consulta.
La forma en que se realizan consultas a una base de datos empleando el lenguaje SQL es a través de sentencias en dicho lenguaje. Una sentencia SQL de consulta tendrá habitualmente una forma como la siguiente:
SELECT lista_de_columnas FROM nombre_de_tabla WHERE expresión_condicional
Lista_de_columnas es una lista con los nombres de los campos que nos interesa incluir en la tabla resultante de la consulta, nombre_de_tabla es el nombre que identifica la tabla de la que queremos tomar los datos, y expresión_condicional un predicado que establece la condición que han de cumplir los registros a tomar.
Como vemos, no es muy distinto de lo que hemos visto hasta ahora, y simplemente es otra forma de plantear consultas, de modo similar a lo que conocemos. La flexibilidad del lenguaje y la adición de funciones y nuevas ordenes permiten, no obstante, expresar prácticamente cualquier consulta, por compleja que esta sea, y extraer todo el potencial de la base de datos.
Sin animo de resultar un repaso exhaustivo a todos los elementos del lenguaje (ello requeriría mucha más extensión que todo este capítulo), a continuación se muestran algunos ejemplos de expresiones SQL explicados después en lenguaje natural, para dar una idea de la forma y capacidades del lenguaje. Una vez más, se anima al lector interesado a consultar las referencias propuestas para mayores detalles. Para estos ejemplos utilizaremos la tabla de países cuya estructura ya hemos presentado al comienzo de este capítulo.
SELECT * FROM Paises WHERE Moneda = 'Euro' AND Poblacion_actual > 40000000
Esta consulta recupera todos aquellos registros en los que la población actual supera los 40 millones y la moneda es el euro. El asterisco indica que, para cada uno de estos registros, deben recuperarse todos los campos existentes. Se podría formar una nueva tabla solo con los nombres de los países que cumplen la condición establecida, mediante la siguiente sentencia:
SELECT Nombre FROM Paises WHERE Moneda = 'Euro' AND Poblacion_actual > 40000000
Las consultas pueden ser mucho más complejas, y las sentencias SELECT pueden usarse como parámetros dentro de un predicado lógico. Por ejemplo, supongamos que disponemos de una tabla denominada Capitales con datos de todas las capitales del mundo, y que cuenta con los siguientes campos:
- Nombre - Poblacion_hombres - Poblacion_mujeres
La sentencia siguiente recupera en una nueva tabla todos los países cuyas capitales tienen una población de hombres mayor que de mujeres.
SELECT Nombre FROM Paises WHERE Capital IN (SELECT Nombre FROM Capitales WHERE Poblacion_hombres > Poblacion_mujeres)
La subconsulta entre paréntesis crea una tabla con los nombres de las capitales que cumplen la condición relativa a las poblaciones de hombres y mujeres. La otra consulta selecciona los países cuya capital aparece en dicha tabla (esa inclusión la define el comando IN ). En conjunto, tenemos una única consulta, pero que se basa en dos tablas con una relación entre sí.
Los campos Capital en la tabla Países y Nombre en la tabla Capitales son los que establecen la relación entre ambas tablas, permitiendo unir la información de estas. No obstante, el resultado de la expresión anterior no es una unión tal y como la hemos visto. Para realizar una unión mediante SQL podemos utilizar una expresión como la siguiente:
SELECT * FROM Paises, Capitales WHERE Paises.Capital = Capitales.Nombre
Como se dijo, las uniones no se limitan un tipo particular de unión como el que vimos. SQL incluye el comando JOIN , el cual permite trabajar con todo ese abanico de distintas uniones.
Además de lo anterior, pueden emplearse operadores para que la tabla que constituye la respuesta a la consulta contenga campos adicionales calculados en función de los existentes en la tabla origen. Por ejemplo:
SELECT Nombre, Poblacion / Area AS Densidad FROM Paises WHERE Moneda = 'Euro'
Esta consulta recupera todos los países donde la moneda utilizada es el Euro, y para cada uno de ellos define dos atributos: el nombre (directamente obtenido de la propia tabla de países) y la densidad (en un campo denominado DENSIDAD , calculado como el cociente entre la población y el área).
En resumen, el lenguaje SQL permite expresar todo tipo de consultas y hacerlo de forma sistemática y relativamente sencilla, de una forma bastante similar a como lo haríamos en un lenguaje natural.
Consultas espaciales
Ahora que ya sabemos cómo sacar partido de los atributos (es decir, la componente temática), es hora de incorporar la componente espacial que se asocia a estos. A las consultas que pusimos como ejemplo en la sección anterior, podemos añadir otras como las siguientes:
- ¿Qué países comparten frontera con Alemania?
- ¿Cuántos países se encuentran completamente en el hemisferio sur?
- ¿Qué países están a menos de 2000 km de España?
Para dar respuesta a esas cuestiones, basta analizar la componente espacial sin necesidad de recurrir a los datos temáticos con los que hemos trabajado anteriormente. Son consultas puramente espaciales. Aunque estas consultas amplían lo que ya conocemos, en realidad no abren ninguna nueva vía de estudio de los datos geográficos. Son consultas a las que podríamos responder utilizando un mero mapa impreso, sin aprovechar el hecho de que, como hemos visto, dentro de un SIG las componentes espacial y temática se hallan íntimamente vinculadas.
La verdadera potencia de las consultas espaciales la encontramos en la combinación de estas consultas sobre la componente espacial y las que vimos anteriormente sobre la componente temática. Así, se pueden plantear, por ejemplo, cuestiones como:
- ¿Qué países del hemisferio norte tiene una densidad de población mayor que la de Perú?
- ¿Cuántos países con más de 10 millones de habitantes se encuentran a menos de 1000 km de la frontera de Rusia?
Estas consultas incorporan elementos que hacen necesario acudir a la tabla de atributos, y otros que requieren analizar la componente espacial, estudiando las relaciones espaciales y topológicas de las geometrías asociadas.
Los lenguajes de consulta pensados para el trabajo exclusivo con datos no espaciales no permiten formular consultas que incorporen elementos espaciales, y por lo tanto no resultan suficientes para expresar las anteriores cuestiones. Tanto las bases de datos como los lenguajes de consulta son válidos para analizar la componente temática, pero no para el análisis global de ambas componentes tal y como este ha de llevarse a cabo dentro de un SIG, por lo que es necesario añadir elementos adicionales.
Sin embargo, no es solo mediante un lenguaje de consulta como podemos plantear dichas consultas espaciales a través de un SIG. Al igual que en el caso de la componente temática, a la hora de efectuar consultas sobre la componente espacial o bien sobre ambas conjuntamente, existen diversas formas de plantear dichas consultas, algunas de ellas mucho más inmediatas y sencillas. En el caso particular de la componente espacial, y por la propia naturaleza de esta, que puede ser representada gráficamente, la forma más simple de efectuar una consulta es, precisamente, de forma gráfica.
Este es el mismo mecanismo que emplearíamos a la hora de trabajar con un mapa impreso clásico. Si señalamos sobre nuestro mapamundi y preguntamos ¿qué país es este ?, estamos estableciendo física y visualmente el criterio de consulta con nuestro propio dedo. Dentro de un SIG, podemos hacer clic con el ratón (nuestro dedo dentro de dicho SIG) en un determinado punto de la representación en pantalla de una capa geográfica, y realmente estamos diciendo: ¿qué entidad de la capa es la que hay aquí ? o ¿qué entidad es esta ?
Al hacer esto, estamos empleando las relaciones espaciales que veíamos en el capítulo Analisis_espacial , y en particular en este caso la inclusión de un punto dentro de un polígono. Al efectuar la consulta, el SIG comprueba si el punto definido por nuestro clic de ratón se encuentra dentro de los polígonos que representan cada país. Si eso es así, el país en cuestión queda seleccionado.
Una vez más, no debe pensarse que esta consulta puntual es exclusiva de los datos vectoriales. Podemos igualmente ir a una localización dada y preguntar por lo que hay en dicha localización con independencia del modelo de datos. Una capa ráster nos devolverá sencillamente el valor en la celda que cae en el emplazamiento señalado. Si la capa posee varias bandas, tal como una imagen multiespectral, nos devolverá un vector de valores correspondientes a los valores de todas las bandas en dicho punto.
Como veremos en el capítulo Servidores_y_clientes_remotos dedicado a servicios remotos, algunos de estos servicios nos permiten realizar consultas igualmente sobre datos ráster y coberturas. En cada punto de la cobertura tenemos una información compleja, que podemos recuperar del mismo modo que para otro tipo de capas, sin más que preguntar a dicha cobertura acerca los datos correspondientes a un punto dado.
La consulta sobre capas no vectoriales es, sin embargo, menos interesante, pues el mayor interés aparece cuando consideramos entidades en el modelo geográfico y efectuamos consultas sobre las propiedades espaciales de dichas entidades. El modelo vectorial es el mejor adaptado a las consultas, no solo cuando trabajamos con la componente temática, como ya vimos, sino igualmente cuando se trata de consultas puramente espaciales.
La consulta sobre un punto concreto que hemos descrito la incorporan la gran mayoría de los SIG y es una herramienta de primer orden, sumamente sencilla, que nos permite hacer un uso simple aunque muy práctico de los datos geográficos. No obstante, una consulta espacial de este tipo puede ser más compleja e incorporar en el criterio algo más que un único punto. Por ejemplo, podemos seleccionar todas las entidades dentro de un área rectangular, o bien dentro de un polígono cualquiera que podríamos definir directamente sobre la propia representación en pantalla (Figura \ref{Fig:Seleccion_rectangulo}).
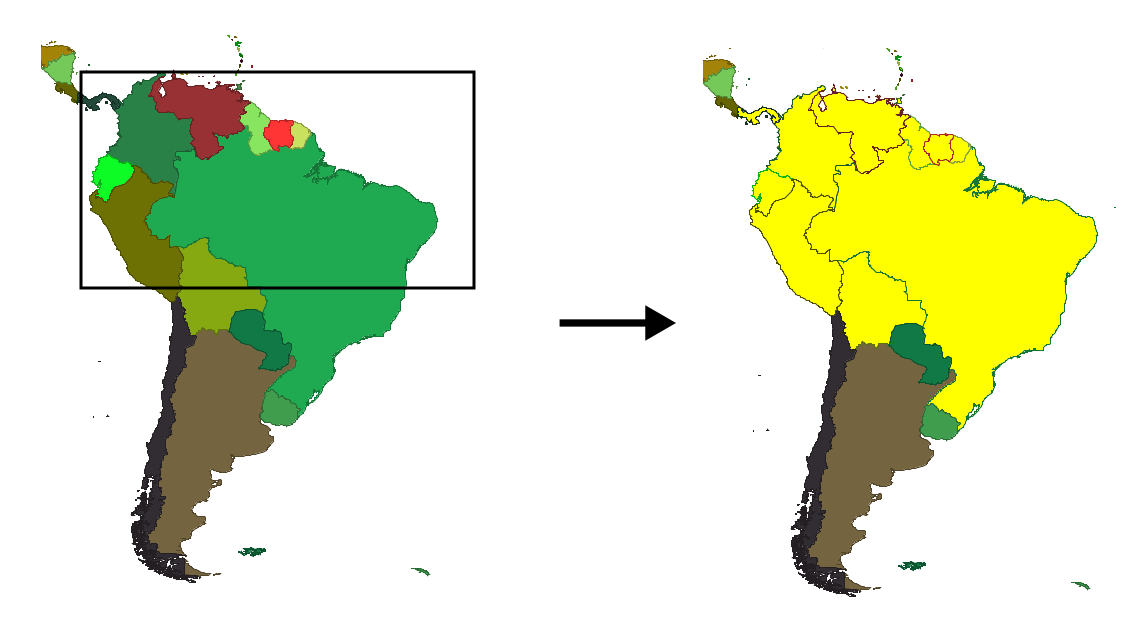
Las relaciones que utilizamos en este caso ya no son entre punto y polígono, sino entre polígonos. La selección puede incluir tanto los países que se encuentran por completo contenidos dentro del polígono, como aquellos que intersecan con este. Es decir, que podemos aplicar varias de las relaciones que en su momento estudiamos entre dos polígonos.
Además de poder efectuar estas consultas con un elemento tal como un punto o un polígono, también podemos valernos de otra capa con sus propias geometrías. Por ejemplo, si disponemos del contorno del continente europeo, podemos consultar la capa de países del mundo y ver cuáles se encuentran en Europa. O una capa de ríos del mundo nos valdría para responder a la pregunta «¿qué países atraviesa el Nilo?»
Las relaciones espaciales entre las entidades de varias capas pueden emplearse para efectuar una selección, pero también para otra de las operaciones importantes que veíamos en el caso de la componente temática: la unión. En aquel caso, se establecían las relaciones entre tablas de acuerdo a un predicado relativo a la propia información de las tablas (en la mayoría de los casos, que los valores de dos campos, uno en cada tabla, fueran coincidentes). La incorporación de la componente espacial implica la aparición de predicados espaciales, y estos pueden emplearse del mismo modo que los no espaciales para definir un criterio de unión.
Un ejemplo muy sencillo de unión espacial es el que encontramos si combinamos la capa de países del mundo que venimos utilizando con una capa de ciudades del mundo. Podemos unir a la tabla de esta segunda capa todos los valores que caracterizan al país al que pertenece cada ciudad. Si existe un campo común entre ambas tablas de atributos (por ejemplo, el nombre del país), esto serviría para efectuar esta unión. No obstante, esto no es necesario, ya que existe otro elemento común que no se encuentra almacenado dentro de la tabla, pero que puede tomarse de la componente espacial: toda ciudad debe estar situada dentro de los límites del país al que pertenece. Esto sirve para establecer la relación entre las tablas, y cada ciudad debe relacionarse con aquella entidad dentro de cuya geometría se encuentre el punto que la representa.
De modo similar a como ocurría con las operaciones temáticas, todas estas operaciones pueden llevarse a cabo en un SIG mediante herramientas sencillas que se encargan de efectuar las selecciones o uniones, utilizando tanto elementos gráficos como textuales. Disponemos así de herramientas de consulta temática y herramientas de consulta espacial, ambas como utilidades independientes. Podemos, sin embargo, dotar de mayor potencia a las realización de consultas si combinamos ambas componentes del dato geográfico.
Es en este punto donde los lenguajes de consulta que ya hemos visto hacen su aparición. Estos lenguajes han demostrado ser idóneos para el manejo de las bases de datos, y resulta lógico pensar en ellos como base para un lenguaje más potente que permita incorporar la componente espacial a las consultas. Tenemos de este modo los lenguajes de consulta espacial
Lenguajes de consulta espacial
Los lenguajes de consulta espacial son la extensión lógica de los lenguajes de consulta con objeto de adaptarse al manejo de datos espaciales. Del mismo modo que las bases de datos han de adaptarse para almacenar los datos espaciales, como ya vimos en el capítulo dedicado a estas, los lenguajes de consulta deben hacer lo propio para ser capaces de recoger aquellas consultas que hagan un uso explícito de las propiedades espaciales de los objetos almacenados.
El lenguaje SQL que ya conocemos no resulta suficiente para expresar algunas de las consultas presentadas en el apartado anterior, pero sin embargo sigue siendo de utilidad para consultas no espaciales. Las extensiones al lenguaje SQL constituyen la forma más inmediata de obtener un lenguaje de consulta espacial adecuado para un uso completo, pues combinarán nuevas capacidades de consulta espacial con aquellas de tipo no espacial del lenguaje SQL, probadamente robustas.
Un primera solución aparece con la revisión del lenguaje SQL llevada a cabo en 1999 (conocida como SQL:1999 o SQL3), en la cual se permite la creación de tipos personalizados de datos. Frente a los tipos originales tales como enteros, cadenas o valores booleanos, todos ellos poco adecuados para almacenar objetos espaciales, existe ahora la posibilidad de crear tipos más acordes con la naturaleza espacial de la información almacenada. SQL3 está orientado a objetos, y cada tipo puede tener una serie de métodos asociados, lo cual facilita la realización de consultas complejas.
El problema radica en que la propia flexibilidad de este mecanismo no favorece la unicidad necesaria para la interoperabilidad de los datos. Un mismo tipo puede implementarse como tipo SQL de muchas formas distintas, no siendo estas compatibles entre sí. Es ahí donde hacen su aparición los estándares, los cuales veremos con más detalle en el capítulo Estandares .
De especial importancia en este sentido es la norma denominada Simple Features for SQL , que especifica cómo han de implementarse los tipos SQL correspondientes a los objetos espaciales, con objeto de estandarizar esta implementación. Así, una base de datos incorporará dichos tipos en sus modelos y estos podrán ser posteriormente utilizados para la realización de consultas SQL. En el ya citado capítulo Estandares explicaremos en detalle este y otros estándares.
El aspecto más importante para el contenido de este apartado no es el modelo de datos u otras características de la base de datos en sí (vimos esto ya con más detalle en el capítulo Bases_datos ), sino la forma en que esto afecta a la realización de consultas. Por ello, la parte de mayor interés son los métodos que esos tipos implementan, y que pueden emplearse para dar forma a consultas espaciales como las que veíamos en el apartado previo.
Estos métodos vienen también especificados por la norma Simple Features, y como ya veremos podemos dividirlos en tres grupos: funciones básicas, operaciones topológicas y de conjunto, y operaciones de análisis espacial. Los resultados que arrojan estos métodos se pueden emplear para dar forma a consultas que realizan operaciones como la selección o la unión. Ya vimos cómo llevar estas a cabo mediante consultas SQL, y los ejemplos con contenido espacial del apartado son también operaciones de este tipo, bien sean consultas o uniones. Veamos, pues, cómo podrían realizarse mediante consultas SQL empleando los métodos que han de presentar los tipos que cumplen la especificación Simple Features.
Por ejemplo, para ver qué países atraviesa el río Nilo, podemos emplear una consulta como la siguiente:
SELECT Paises.Nombre, FROM Rios, Paises WHERE Cross(Rios.shape, Paises.Shape) AND Rios.Nombre = 'Nilo'
La expresión Cross(Rios.Shape, Paises.Shape) hace uso del método Cross , que devuelve 1 en caso de que las dos geometrías pasadas como parámetros se intersequen, y 0 en caso contrario. Este se utiliza para realizar la selección solo sobre aquellas que cumplan la condición de ser cortadas por una geometría dada, en este caso la del río Nilo.
La relación espacial entre el río y los distintos países no puede evaluarse haciendo uso de SQL sin extensiones espaciales, puesto que sin ellas no es posible interpretar correctamente las geometrías almacenadas en la base de datos y proceder con ellas a calcular las correspondientes intersecciones.
Algunos métodos como el método Cross anterior expresan condiciones, y al evaluarse devuelven valores 1 o 0 (verdadero/falso). Otros dan como resultados tipos distintos de valores, entre los que pueden estar nuevas geometrías.
Un ejemplo de esto podemos verlo al combinar el método Length , que devuelve un valor numérico correspondiente a la longitud de una línea, con el método Intersection , que devuelve una nueva geometría a partir de la intersección de otras dos. Mediante ambos, podemos resolver la consulta anterior pero añadiendo en la tabla resultado no solo el nombre de los países que son atravesados por el Nilo, sino también la distancia que este río recorre a través de cada uno de ellos.
La consulta tendría en este caso una forma como la siguiente:
SELECT Paises.Nombre, Length(Intersection( Rios.Shape, Paises.Shape)) AS 'Longitud' FROM Rios, Paises WHERE Cross(Rios.Shape, Paises.Shape) AND Rios.Nombre = 'Nilo'
Al igual que en el apartado anterior, el objetivo de este apartado no es mostrar con detalle la sintaxis del lenguaje SQL cuando este se emplea para la realización de consultas espaciales. Los anteriores son únicamente algunos ejemplos para poner de manifiesto la potencia de este planteamiento y mostrar cómo los elementos espaciales se integran en el lenguaje SQL. Puede encontrarse más información en [ Egenhofer1994IEEE ].
Además de esta extensión a SQL, existen otras propuestas alternativas tales como Geo--SQL, SSQL (Spatial SQL) o SQL-MM.
Índices espaciales
Si realizamos una consulta a una base de datos, el resultado es un subconjunto de esta con los elementos que cumplen el criterio expresado en la consulta. Si se implementa de forma directa dicha consulta, esta operación implica comprobar todos los elementos de la base de datos y ver cuáles son los que cumplen con el citado criterio. Teniendo en cuenta que una base de datos puede tener un gran tamaño, esta forma de proceder no es la óptima.
Veamos un ejemplo para poder entender mejor esto. Supongamos que tenemos una guía telefónica, que no es sino una base de datos en la que cada registro contiene dos campos: nombre y apellidos, y teléfono. ¿Cómo buscaríamos en esa guía telefónica el numero de una persona llamada Juan Pérez? Sin duda, leyendo uno por uno todos los nombres acabaríamos encontrando el que buscamos y su número correspondiente, pero antes tendríamos que leer una gran cantidad de nombres y apellidos (más aún en este caso, considerando que la letra P se encuentra en la mitad final del alfabeto), con lo que no resulta una opción muy lógica. En tal caso, una guía telefónica sería una herramienta inútil.
Sin embargo, habitualmente consultamos guías telefónicas sin problemas y encontramos rápidamente el teléfono de una persona sin necesidad de leer más que unos pocos nombres. Esto es así porque sabemos cómo están dispuestos los datos y buscando en el índice sabemos incluso en qué página comienzan los apellidos con una letra dada (en este caso la letra P). El uso de este índice nos permite optimizar el proceso de búsqueda de una forma realmente radical.
Al utilizar una base de datos, si no disponemos de un índice deberemos recorrer toda ella para dar respuesta a nuestras consultas. No sabemos dónde buscar las respuestas a nuestras consultas, del mismo modo que si en una guía telefónica no supiéramos que carece de sentido buscar en la letra F el número telefónico del señor Pérez.
Los índices nos permiten alcanzar los elementos que constituyen la respuesta a nuestra consulta, haciéndolo de la forma más rápida y llegando hasta ellos sin tener que pasar por todos los restantes.
Describir los índices empleados en bases de datos no espaciales requiere describir asimismo estructuras de datos complejas que escapan del alcance de este texto (los denominados árboles B+ son las estructuras utilizadas con más frecuencia para esta tarea). Por esta razón, no se detallarán en este capítulo más allá de la anterior descripción básica, pudiéndose encontrar más información en las referencias proporcionadas a lo largo del capítulo.
Más interesantes que estos índices nos resultan aquellos que se utilizan en las bases de datos espaciales, que denominamos índices espaciales . El concepto es similar al de índices de bases de datos no espaciales: elementos que permiten optimizar las consultas mediante una correcta estructuración de los datos, en particular en este caso de su componente espacial.
Los índices espaciales no deben resultarnos desconocidos, ya que los vimos en el capítulo Tipos_datos , estudiando en su momento los tipos existentes y su proceso de creación. Ahora en este capítulo veremos el verdadero uso práctico de estos, y así podremos comprender mejor la necesidad de su existencia.
Puede entenderse igualmente la idea de un índice espacial mediante un sencillo ejemplo de cómo empleamos ideas parecidas a los índices espaciales de forma natural cuando tratamos de resolver una consulta espacial sin la ayuda de un SIG. Supongamos que tenemos nuestro mapa de países del mundo y queremos averiguar qué países tienen su frontera a menos de 2000 kilómetros de la frontera de España. ¿Cómo operaríamos de manera natural para dar respuesta a esta consulta?
La solución más inmediata es medir la distancia entre España y todos los países restantes, y después tomar aquellos que hayan arrojado un resultado de distancia menor a 2000. La operación daría el resultado esperado, pero implicaría un gran número de mediciones, y no sería una forma óptima de operar. De hecho, es probable que a nadie se le ocurriese operar de esta forma en ningún caso. Por ejemplo, lo más probable es que no efectuemos mediciones con los países de América, pues un conocimiento básico de geografía basta para saber que todos ellos se encuentran a más de 2000 kilómetros. No sabemos exactamente a qué distancia se encuentran, pero sabemos que de ningún modo van a cumplir el criterio establecido en la consulta. De modo similar podemos eliminar Australia y gran parte de Asia, porque se encuentran en una situación similar.
Ese conocimiento básico de geografía que tenemos es en realidad una especie de índice espacial. No sirve para saber las distancias exactas ni resolver la consulta por completo, pero sirve para dar una aproximación y facilitar el trabajo. Descartamos un buen numero de países de forma casi inmediata, y luego solo realizamos las operaciones costosas (la medición) con un subconjunto del total. En nuestra mente, tenemos el conocimiento estructurado a distintos niveles. Incluso si memorizamos todas esa distancias, existe otro nivel más general de conocimiento, a otra escala, siendo este el que nos indica de forma rápida que toda América está fuera de la distancia establecida en la consulta y no merece la pena efectuar mediciones referidas a países de ese continente.
Con la utilización un índice espacial, el proceso de consulta espacial se compone de dos subprocesos: filtrado y refinamiento [ Freksa1991Kluwer ]. En el proceso de filtrado se hace una primera selección aproximada de entidades, las cuales son candidatas a cumplir los criterios de la consulta. Se reduce de este modo el número de elementos sobre los que se ha de trabajar, y esta reducción, apoyada en los índices espaciales, tiene un coste operacional menor que aplicar la consulta en sí a todos los elementos.
En el refinamiento, se toman los elementos que han superado la fase de filtrado, y sobre ellos se aplica la consulta como tal. Esto tendrá como consecuencia que algunos de estos elementos, pese a haber pasado la primera fase de filtrado, no cumplan el criterio de la consulta, ya que este filtrado era una aproximación al resultado final. De esta forma refinamos este resultado previo y obtenemos ya la respuesta exacta a la consulta formulada.
En resumen, se puede decir que los índices espaciales nos permiten obtener resultados en un área concreta sin necesidad de analizar todo el espacio ocupado por el total de los datos. Estos índices espaciales no son exclusivos del trabajo con bases de datos y la realización de consultas espaciales, sino que se encuentran implícitos en muchas operaciones que vamos a ver en los próximos capítulos dentro de esta parte del libro. Estas operaciones en realidad necesitan para su desarrollo efectuar algún tipo de consulta, y dicha consulta depende de los índices espaciales para ejecutarse con un buen rendimiento.
Por ejemplo, las funciones de interpolación, que veremos en el capítulo Creacion_capas_raster , para calcular el valor en una coordenada concreta, y a partir de los valores de una capa de puntos, habitualmente utilizan los $n$ puntos más cercanos a dicha coordenada. Para saber cuáles son estos $n$ puntos, podrían calcularse las distancias desde todos los puntos de la capa hasta la coordenada en cuestión, y después tomar los $n$ para los cuales esa distancia es menor. Esta forma de proceder, sin embargo, requiere un número de cálculos demasiado elevado, que haría imposible ejecutar en un tiempo lógico dichos algoritmos de interpolación cuando los puntos de la capa sean numerosos (lo cual es muy frecuente).
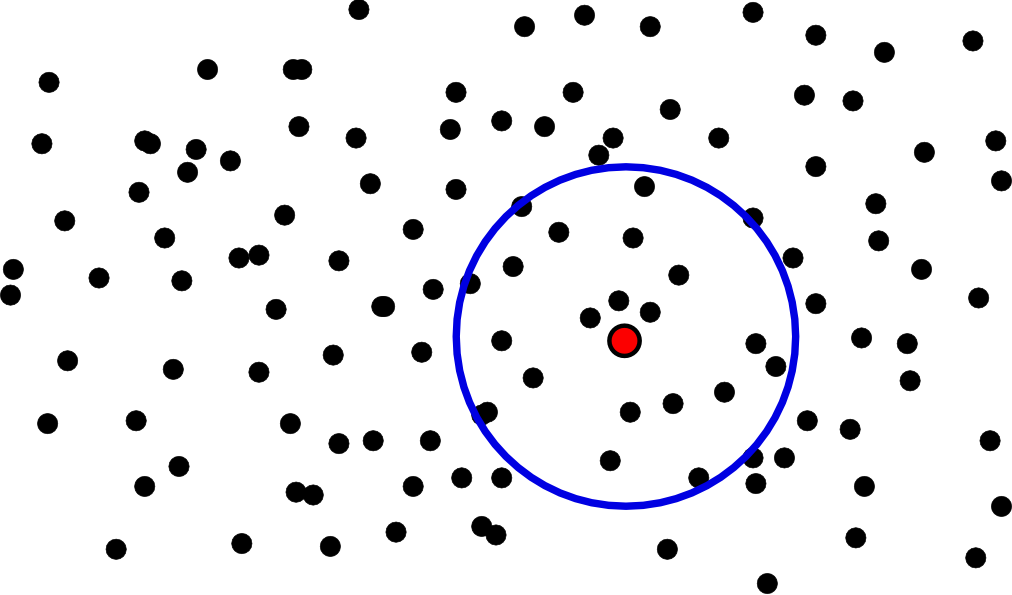
Si vemos la figura \ref{Fig:Ej_indices_espaciales}, para calcular cuales son los diez puntos (en negro) más cercanos a una coordenada dada (en rojo), no mediríamos las distancias de todos ellos. Mirando a simple vista podemos estimar que esos puntos van a estar dentro de un círculo aproximadamente como el representado en la figura, y podemos prescindir de los restantes a la hora de calcular las distancias exactas. Dentro de ese circulo hay más de diez puntos, con lo cual debe refinarse ese resultado antes de poder ofrecer una respuesta exacta a la consulta.
Otros procesos en los que son vitales los índices espaciales son las operaciones de solape entre capas de polígonos, que veremos en el capítulo Operaciones_geometricas . Sin ellos, el rendimiento de estas operaciones espaciales sería mucho menor o incluso, como en el caso de la interpolación, totalmente insuficiente para que tales operaciones se puedan aplicar en la mayoría de los casos.
Resumen
Las consultas son uno de los análisis fundamentales dentro de un SIG. Básicamente, una consulta efectúa una pregunta acerca de la información contenida en una capa, y obtiene como resultado los elementos de la capa que dan respuesta a dicha pregunta. Las consultas son en general un elemento aplicado sobre capas vectoriales, y el resultado de la consulta se expresa mediante una selección de entidades dentro de aquellas que componen dicha capa.
Las consultas pueden efectuarse sobre la componente temática del dato geográfico, en cuyo caso emplean los mismos mecanismos que las bases de datos fuera de un SIG. Esto incluye el empleo de lenguajes de consulta, específicamente desarrollados para esta tarea. El lenguaje SQL (Structured Query Language) es el más habitual de estos.
Al incorporar la componente espacial, se añaden nuevos elementos para realizar consultas. Los criterios de consulta añaden predicados espaciales basados en las relaciones entre las distintas entidades, y estos a su vez pueden combinarse con los predicados no espaciales para la formulación de consultas complejas. Los lenguajes de consulta se extienden para dar cabida a estos nuevos predicados, así como a funciones espaciales basadas en las propias entidades de las capas.
La aplicación de criterios espaciales hace necesaria la utilización de índices espaciales para optimizar el trabajo con grandes volúmenes de datos. Estos índices estructuran los datos de tal modo que en la realización de consultas espaciales no es necesario efectuar dicha consulta sobre la totalidad de los datos, sino únicamente sobre una fracción de ellos.