Servidores remotos y clientes. Web Mapping
Olaya, Víctor; Turton, Ian; Fonts, Oscar
Introducción
Del mismo modo que podemos acceder a otros tipos de información a través de Internet o de una red local, también podemos emplear esta para acceder a información geográfica y trabajar con ella dentro de un SIG. En el contexto actual, no puede dependerse en un SIG únicamente de datos locales en forma de archivos en el mismo ordenador en el que se trabaja, sino que es necesario poder operar con datos remotos. Las redes son la vía para la difusión de todo tipo de información, entre ella la información geográfica.
Los datos espaciales pueden ofrecerse a través de una red de la misma manera que se ofrecen otro tipo de datos como imágenes o texto en una pagina Web. Para que en este proceso se maximicen las posibilidades que esos datos ofrecen, es necesario disponer de tecnologías adaptadas, particularizadas al tipo concreto de datos que se maneja y los posibles usos que pueden darse.
Estas tecnologías son variadas y, como cabe esperar, han evolucionado paralelamente a otras basadas en la Web, añadiendo progresivamente elementos tales como una mayor interactividad o flexibilidad. Las páginas estáticas que formaban Internet hace unos años, muy limitadas en cuanto a sus posibilidades, han dado paso a lo que hoy se conoce como Web 2.0, donde encontramos blogs , wikis y otros tipos de páginas con capacidades mucho mayores y que permiten al usuario un trabajo muy distinto.
Una evolución similar han seguido las aplicaciones de la Web relacionadas con la información geográfica, que han ganado en riqueza hasta el estado actual donde pueden llegar a ofrecer casi tantas funcionalidades como un SIG de escritorio. Los mapas estáticos que constituían los primeros elementos con componente geográfica en la Web han evolucionado hasta verdaderas aplicaciones que pueden convertir un navegador en una plataforma SIG completa. En su avance, las tecnologías Web van tomando elementos que ya conocemos de los SIG de escritorio, con objeto de trasladar toda su potencia al entorno de Internet, y uniéndola así con las capacidades que la red tiene como espacio común de actividad y conocimiento.
Aunque el objetivo final sea trasladar los SIG de escritorio a la red, las tecnologías necesarias distan bastante de las tecnologías SIG en sentido clásico, de la misma forma que, aun trabajando con un tipo de datos similar, un procesador de textos se diferencia mucho de un navegador Web.
Fundamentalmente, estas tecnologías Web han de responder a dos necesidades principales: servir un elemento a través de la red y tomar este para emplearlo. Es decir, tomar y recibir el elemento que es objeto de interés. Distinguimos así los conceptos de servidor y cliente , que debemos ver con algo más detalle antes de continuar.
¿Cómo funciona Internet?
Estamos acostumbrados a utilizar Internet a través de aplicaciones tales como navegadores Web, y en muchos casos desconocemos cómo se realiza ese proceso tan cotidiano hoy en día. Los fundamentos que residen detrás de la consulta de una simple página Web son esencialmente los mismos que vamos a encontrar para el caso de las tecnologías SIG en la red, por lo que es necesario conocerlos al menos someramente para poder entender el proceso que tiene lugar cuando empleamos una tecnología SIG en Internet.
Cuando consultamos una página Web existen tres elementos fundamentales que entran en juego: la propia red que hace de nexo entre sus elementos, nuestro ordenador que es el que realiza la petición de consulta, y la máquina donde se encuentra almacenada esa página que queremos consultar.
Conocemos como servidor al elemento encargado de servir algún tipo de contenido. En el ámbito SIG, se trata fundamentalmente (aunque no con carácter exclusivo) de datos geográficos, que constituyen el principal producto que se distribuye a través de la red dentro de nuestro campo. En el ejemplo anterior, la máquina que contiene la página de interés es el servidor. También se conoce como servidor el programa que, residiendo en esa máquina, interpreta la petición y la procesa, sirviendo así la página.
El cliente es responsable de pedir ese dato al servidor, tomarlo y trabajar con él. Nuestro navegador Web es el cliente en este caso, ya que es el que realiza la petición. Para ello, basta con introducir la dirección Web correspondiente en la barra de direcciones del navegador. Al hacer esto, proporcionamos una serie de datos que son los que se emplean para realizar el proceso, y que vamos a ver a continuación en detalle.
Supongamos la siguiente dirección Web:
https://librosiglibre.es/descarga
Si visitas esa página estás efectuando una petición a través de esa URL, la cual se compone de las siguientes partes:
- http : El protocolo a usar, que define la forma en que se van a comunicar cliente y servidor. Aunque este es el más habitual, existen muchos otros tales como ftp o mailto .
- librosiglibre.es : Esta cadena identifica la máquina donde reside la página que buscamos. Es en realidad una versión más legible para el ojo humano de un código numérico que indica la dirección concreta. El navegador lo convierte en realidad en algo como 128.118.54.228.
- descarga : La página que buscamos dentro de todas las que hay en esa máquina. Se expresa como una ruta a partir del directorio raíz del servidor, que no es necesariamente el directorio raíz de la maquina servidora.
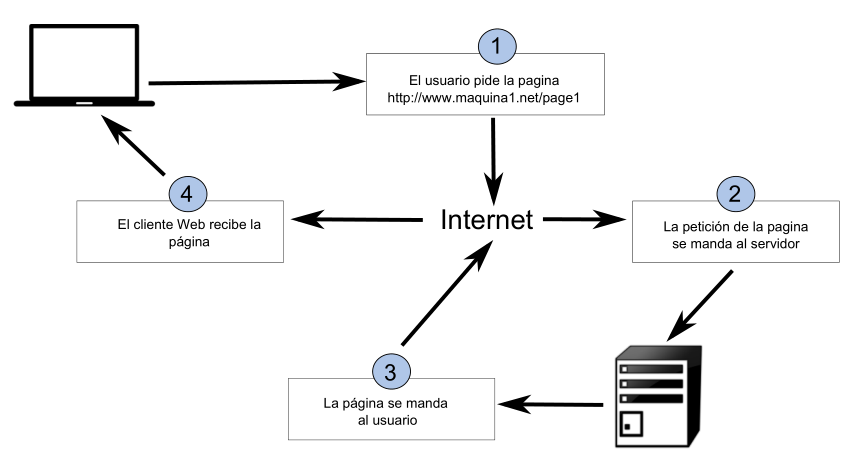
El proceso mediante el que podemos ver esa página en un navegador Web comprende los cuatro pasos siguientes:
- El cliente realiza la petición.
- La petición se conduce a través de la red hasta el servidor.
- El servidor busca la página y la devuelve a través de la red en caso de encontrarla, o devuelve una pagina de error en caso de no tenerla.
- El cliente recibe la página y la representa.
La figura \ref{Fig:Asi_funciona_internet} muestra un esquema de este proceso.
El valor de las tecnologías SIG Web
Antes de abordar la parte más técnica de las tecnologías Web SIG, veamos el significado de estas y la función que cumplen. Entenderemos en este contexto como tecnologías Web SIG a todos aquellos elementos que permiten la representación de cartografía como un contenido más de una página Web. Esto es lo que se engloba bajo la denominación genérica de Web Mapping .
Aunque este capítulo está dedicado a las tecnologías Web dentro del ámbito SIG, y estas incluyen tanto servidores como clientes, las formas en las que se presentan los elementos del Web Mapping dependen fundamentalmente del cliente, el cual es en general un simple navegador.
Como vimos en el capítulo dedicado a los SIG de escritorio, estos pueden acceder a datos remotos, y para ello necesitan realizar una petición a un servidor siguiendo el esquema que hemos visto en el apartado anterior. Una vez que los datos están en el SIG (es decir, el servidor ha devuelto a este los datos que había pedido), podemos operar con ellos usando las herramientas que ya conocemos.
En un entorno Web sensu stricto tal como el de un navegador, las posibilidades son, no obstante, distintas, pues se trata de combinar los elementos cartográficos con los restantes elementos que forman parte habitual de una página Web. Las tecnologías Web de corte SIG se han desarrollado principalmente para su trabajo dentro de un navegador, es decir, como una alternativa a los SIG de escritorio o para alcanzar áreas nuevas en el trabajo con información geográfica digital. Su incorporación en los SIG de escritorio aumenta las capacidades de estos, pero la principal potencia de estas tecnologías surge cuando se unen a otras funcionalidades de tipo Web.
En resumen, el objetivo básico que pretenden cumplir las tecnologías que vamos a ver, especialmente las del lado del cliente, es llevar las funcionalidades de un SIG a la Web, para así compartir la potencia de ambos componentes. Las ventajas de llevar el SIG a la Web en lugar de incorporar los elementos de esta última en un SIG de escritorio tradicional son notables, y existen grandes diferencias entre las soluciones que se obtienen en ambos casos. Estas diferencias tienen que ver sobre todo con los usuarios y su perfil, así como con el diseño mismo de las aplicaciones.
Mientras que un SIG de escritorio se orienta principalmente a usuarios más especializados, poder dotar a un sencillo navegador Web de capacidades de visualización o edición de información geográfica hace que estos lleguen a un público distinto y abre nuevas posibilidades. Los usuarios avanzados encuentran igualmente utilidad en el Web Mapping , que se complementa en muchos terrenos con los SIG de escritorio. Por su parte, los usuarios no especializados, desconocedores de otras tecnologías SIG, pueden incorporarse al ámbito SIG a través de las tecnologías Web.
Algunas de las ideas fundamentales que caracterizan a las tecnologías de Web Mapping y su papel actual son las siguientes:
- No es necesario un software SIG específico . Al menos, no es necesario desde el punto de vista del usuario, que no ha de instalar nada adicional en su ordenador. Acceder a cartografía remota e incluso a funcionalidades avanzadas basadas en esos datos no requiere más que un simple navegador Web, algo presente en cualquier ordenador hoy en día. La barrera que puede suponer el trabajar con una aplicación específica se diluye cuando incorporamos las capacidades de esta en algo tan habitual como un navegador.
- Perfil menos técnico . No solo las aplicaciones están pensadas para su utilización por parte de usuarios no especializados, sino que la incorporación de estos al ámbito SIG hace que la cartografía deje de ser un elemento propio de esos usuarios más técnicos. Poniendo al alcance de todos las capacidades de edición y creación de cartografía hace que cualquiera pueda generar su propia información geográfica no especializada y además ponerla a disposición de otros usuarios.
- Potenciamiento del trabajo colaborativo . La red es un punto de encuentro que favorece de forma natural la colaboración. Proyectos como la Wikipedia, posibles gracias a esta capacidad de Internet para facilitar el trabajo común de múltiples personas, tiene sus equivalentes en el ámbito de la información geográfica. Los SIG dejan de ser algo personal reducido al ámbito de un ordenador o una pequeña red, para ser algo global en una red de muchos SIG interconectados. Y más importante que esto, los datos también se hacen globales, pudiendo ser empleados e incluso editados por todos.
- Información más actualizada , incluso en tiempo real. La Web es el canal ideal para transmitir la información de forma inmediata y flexible. A las ventajas de los datos digitales sobre los analógicos en este sentido, que ya vimos en el capítulo Introduccion_datos , hay que sumar que la sencillez de acceso que aporta una interfaz Web hace todavía más accesible la información geográfica más reciente.
- Independencia del sistema . Un mapa Web puede verse y usarse del mismo modo en cualquier ordenador, con independencia del sistema operativo, el navegador e incluso el dispositivo empleado (PC, móvil, etc.). Si este mapa se basa en estándares abiertos, la solución es todavía más interoperable, como veremos en el apartado Estandares .
- Personalización de aplicaciones . Una de las tendencias más importantes en el ámbito del Web Mapping es la creación de aplicaciones que personalizan una base común para un determinado uso. Sobre una base compuesta por un juego de datos genérico (generalmente imágenes de satélite y mapas base tales como un mapa de carreteras) y una aplicación SIG, se crean pequeñas aplicaciones de forma sencilla, a las cuales se pueden añadir de modo también simple nuevos datos. Estas aplicaciones, una vez creadas, pueden a su vez incorporarse a una página Web distinta. Mediante una de ellas, por ejemplo, un usuario puede crear, sin excesivos conocimientos sobre SIG, una aplicación particular que ponga sobre ese juego de datos general los emplazamientos de todos aquellos que visitan su página Web. Las posibilidades en este sentido son prácticamente infinitas, y proliferan de forma exponencial en Internet.
- Combinación de cartografía y otros elementos . Si llevamos las capacidades SIG a un navegador, además de estas dispondremos en ese navegador de muchas otras posibilidades, tales como la representación de elementos multimedia (vídeo, sonido, etc.) o el uso de hiperenlaces. El navegador es hoy en día la aplicación versátil por excelencia, y ello hace que podamos añadir a las capacidades SIG una larga serie de otras funcionalidades no relacionadas directamente con la información geográfica, y no presentes en su mayoría en los SIG de escritorio.
La importancia de las tecnologías Web se debe, por tanto, principalmente a una razón social y no a una tecnológica, aunque es innegable que las tecnologías novedosas que se desarrollan en este campo aportan al ámbito SIG posibilidades antes desconocidas. Estas nuevas posibilidades enriquecen notablemente los SIG de escritorio si estos implementan las capacidades de acceso a datos remotos, ampliando el alcance de ese tipo de aplicaciones. Cuando se implementan, sin embargo, en un entorno puramente Web tal como en un navegador y se crea una página Web con elementos SIG, se consigue ampliar el abanico de usuarios potenciales y así también crecen las posibilidades y las formas en que el propio SIG puede presentarse.
Formas de cartografía en la Web
Las formas en las que pueden presentarse las tecnologías SIG dentro de un entorno Web varían en cuanto a su similitud con los SIG de escritorio, incorporando más o menos elementos de los que son habituales en este tipo de aplicaciones. Como parece lógico pensar, ha existido una evolución progresiva, de tal modo que en la actualidad existen más elementos propios de los SIG de escritorio dentro de las tecnologías Web SIG, y la cartografía Web hoy en día permite realizar un trabajo más similar al que se desarrolla en un SIG clásico.
Una primera y sencilla clasificación de los tipos de cartografía Web es la que divide esta en mapas estáticos y dinámicos [ Kraak2001Francis ].
Un mapa estático es simplemente una imagen con información cartográfica, la cual no permite ningún tipo adicional de trabajo con ella que no sea la mera observación. En este sentido, se asemeja a un mapa clásico, donde el usuario no puede interactuar directamente con el contenido del mapa. A efectos de trabajo real, las posibilidades son aún menores, ya que acciones tales como mediciones tampoco pueden realizarse, ni siquiera con medios mecánicos como el caso de un mapa en papel. Junto a esto, la resolución de una pantalla común es mucho menor que la que presenta un mapa impreso, con lo que la calidad del mapa no es comparable.
Este tipo de mapas, por tanto, no responden a las funcionalidades que un SIG ha de tener para poder prestar utilidad en el manejo y uso de información geográfica, y difieren notablemente de un SIG de escritorio, incluso en la versión más básica y primitiva de estos últimos.
Incorporar este tipo de mapas a una página Web no requiere ninguna tecnología particular, y puede llevarse a cabo con elementos genéricos tanto del lado del cliente como del servidor, pues el dato realmente no es un dato geográfico, sino una mera imagen (y esa imagen no va acompañada de información tal y como su sistema de referencia), algo para lo cual cualquier servidor o cliente actual ofrece soporte.
La figura \ref{Fig:XeroxPARC} muestra una imagen de una primigenia cartografía Web presentada a través del visor Xerox PARC Map Viewer.
Por su parte, un mapa dinámico es aquel que no se compone de una imagen inmóvil, sino que esta varía y se adapta en función de los requerimientos del usuario o según alguna serie de parámetros prefijados. De acuerdo con esto, los mapas dinámicos pueden ser interactivos o no, dependiendo de si es el usuario quien directamente modifica la representación del mapa.
Como ejemplo de mapa dinámico no interactivo podemos citar mapas animados que encuadran una determinada zona y muestran la variación de una variable a lo largo del tiempo. Mapas de variables climatológicas o una serie animada de mapas que reflejan el avance de un incendio son ejemplos habituales de este grupo.
Tampoco en este tipo de mapas aparecen las funciones esperables en una aplicación SIG, y una vez más no se requieren tecnologías específicas para poder incorporar este tipo de elementos en una página Web.
La interactividad es la que aporta las posibilidades necesarias para comenzar a incorporar funciones SIG a la cartografía Web, y sin ella no podemos hablar en realidad de tecnologías SIG puramente dichas.
La forma de interactividad más básica que se implementa en una página Web en el trabajo con cartografía es la que permite la modificación de la manera en que los datos geográficos se visualizan. Las herramientas que permiten modificar la escala de visualización (acercarse o alejarse) y desplazar el mapa, las cuales ya nombramos como capacidades básicas en los SIG de escritorio, aportan a la cartografía Web muchas posibilidades nuevas. Entre ellas, es de destacar que mediante estas herramientas la extensión de los datos no se encuentra limitada por la propia extensión de la pantalla o la dimensión del navegador.
Si se trabaja con imágenes estáticas, trabajar con datos que cubran toda la extensión del globo implica hacerlo a una escala de muy poco detalle, pues ha de representarse toda la imagen de forma simultanea. Permitiendo que el usuario elija la escala de representación y ajuste la extensión con la que se desea trabajar, un navegador Web se convierte en una ventana hacia datos que pueden tener cualquier extensión y volumen, y hacia el trabajo con ellos de forma dinámica e interactiva.
Esto es de especial importancia si pensamos que las máquinas que se encuentran al otro lado (en el servidor) son ordenadores potentes con gran capacidad, que pueden almacenar enormes conjuntos de datos. Un conjuntos de datos con imágenes de todo el mundo a gran resolución ocupa un tamaño que probablemente lo haga inutilizable en un ordenador personal (además de que esos datos probablemente queden fuera del alcance del usuario de ese ordenador en lo que a su adquisición respecta), pero puede perfectamente almacenarse en un servidor potente, desde el que se servira en cada caso la «porción» de él que cada usuario requiere según utiliza el cliente correspondiente.
De especial importancia para el desarrollo de estas capacidades ha sido la popularización y mejora de las tecnologías que permiten el desarrollo de las denominadas Aplicaciones de Internet Enriquecidas (RIA). Este tipo de aplicaciones llevan a la Web algunos elementos de las tecnologías de escritorio, y en general permiten optimizar el volumen de datos necesario para operar con la aplicación dentro del entorno del navegador.
Si no se emplean estas tecnologías, un cambio mínimo en la configuración de la pagina por parte del usuario (por ejemplo, modificar el encuadre del mapa en una aplicación SIG), requiere la recarga total de la página, de la misma forma que sucede cuando hacemos clic en un hiperenlace. En realidad, estamos pasando a una página Web distinta.
En un entorno RIA, sin embargo, se cargan al inicio (en el primer acceso a la página) los elementos que constituyen la aplicación en sí, y posteriormente se transmiten únicamente los datos que vayan siendo necesarios a medida que el usuario opere con la aplicación. Esto mejora notablemente la sensación del usuario, ya que este nunca tiene ante sí una pantalla sin contenido mientras se carga la página, puesto que esta ya no ha de cargarse de nuevo, y la carga de datos puede además realizarse mientras el propio usuario opera.
Profundizar más en estos aspectos es, no obstante, demasiado técnico para el enfoque de este libro, no siendo necesario además para la comprensión de las tecnologías Web desde el punto de vista del usuario. Tan solo es necesario diferenciar entre el comportamiento de una página Web anterior a la introducción de estas técnicas, en la cual cualquier interacción suponía una recarga completa de la página, mientras que en el caso de una RIA la experiencia es más fluida y cercana a la que se tiene usando una aplicación de escritorio.
La figura \ref{Fig:Tiger} muestra el aspecto de una aplicación de Web Mapping previa a la introducción de esta clase de tecnologías.
Además de modificar la zona representada, un usuario debe poder modificar la forma en que los datos dentro de esa zona se muestran. Es decir, debe poder cambiar el estilo de los elementos representados, variando colores o formas de la misma manera que esto puede hacerse en un SIG de escritorio. Asimismo, muchas aplicaciones Web permiten la consulta de varias capas de datos, incluso de datos provenientes de varios servidores distintos, datos que no necesariamente han de mostrarse todos simultáneamente. Igual que en un SIG de escritorio seleccionamos unas u otras capas para su visualización y podemos alterar el orden de representación de estas, también podemos realizar estas operaciones en una aplicación SIG Web.
Esto hace que una aplicación SIG dentro de un navegador se convierta en una herramienta completa para el acceso a uno o varios juegos de datos remotos cuyo contenido es abundante (no solo en extensión sino también en tipos de datos suministrados), ya que permite una gran configurabilidad y deja en manos del cliente (esto es, del usuario), la forma de tomar esos datos y mostrarlos.
Las capacidades de edición también tienen lugar en los SIG Web, ampliando las posibilidades que la interactividad más básica ofrece. Un usuario puede añadir su propia información a un SIG Web o bien modificar una capa existente empleando su navegador. Las tecnologías SIG siguen en este sentido a las tecnologías Web más generales, adoptando los conceptos de la Web 2.0 y ampliando las posibilidades de los usuarios de colaborar directamente en los contenidos de la red. Por ejemplo, OpenStreetMap es un sitio equivalente a la bien conocida Wikipedia, en el cual los usuarios pueden añadir sus propias descripciones de elementos geográficos que ellos mismos definen.
A estas mismas tecnologías se les puede dar usos más restringidos sin que necesariamente sea dentro de un proyecto colaborativo abierto. Por ejemplo, una administración local puede dar acceso a los propietarios de suelo para que puedan consultar su catastro, mediante un sistema de autenticación conveniente, incluso editar información de sus parcelas. Esta información puede ser de tipo no espacial (es decir, los límites de las parcelas serían fijos), ya que las capacidades de edición no han de limitarse a la componente espacial.
Por último, y aunque en la actualidad son pocos los servicios de este tipo que existen, y no pueden compararse las prestaciones con las que ofrecen los SIG de escritorio, la cartografía Web puede ofrecer herramientas de análisis. Además de representar un conjunto de datos geográficos y permitir al usuario navegar en ellos e incluso editarlos, pueden extraerse resultados a partir de esos datos.
Un tipo de aplicación bastante extendida de este tipo es el cálculo de rutas óptimas. A partir de una capa con vías de comunicación un usuario establece un punto de salida y otro de destino y la aplicación Web calcula la ruta que optimiza el tiempo empleado o la distancia total recorrida, según lo explicado en el capítulo Costes .
El término Web Mapping , habitualmente empleado para designar a la cartografía Web, se sustituye por Web GIS a medida que las capacidades de las aplicaciones Web aumentan, para indicar así que todos los componentes que forman parte de un SIG en su sentido clásico, esto es, un SIG de escritorio, se incorporan a dicha aplicación Web.
Clientes y servidores
Ahora que conocemos algunas ideas generales sobre cartografía Web, veamos algo más en detalle los elementos tecnológicos que hacen posible su funcionamiento: los servidores y los clientes. Veremos en este apartado las funcionalidades que presentan y algo más de los fundamentos tecnológicos en los que se basan, que se apoyan sobre las ideas básicas de funcionamiento de Internet que ya vimos anteriormente.
En el sistema cliente-servidor se presentan las siguientes características principales:
- El servidor brinda servicio a múltiples clientes . Los clientes, por su parte, también pueden acceder a servicios en varios servidores, aunque esa multiplicidad es mucho más relevante en el caso del servidor. Piénsese, por ejemplo, en un navegador Web con el que podemos acceder a varias páginas y un servidor de una de dichas páginas. Mientras que en el cliente no accedemos simultáneamente a un gran número de páginas (si la pagina es estática solo usamos el servicio al cargarla, y no cargamos más de una capa en un instante dado), el servidor debe estar preparado para responder a muchas peticiones simultaneas y satisfacer la demanda de muchos clientes en un instante concreto.
- Los clientes no dependen de la ubicación física del usuario , el sistema operativo o la arquitectura física de la máquina. Esto es así porque el cliente no necesita conocer la lógica interna del servidor para usar sus servicios. Lo único necesario es que el servidor pueda exponer una interfaz externa que actúe como un modo de comunicación para recibir las peticiones del cliente, siendo esta comunicación siempre transparente para este último.
- La carga de proceso se puede repartir entre cliente y servidor . En función del servicio y de las capacidades del cliente, el trabajo puede dividirse de una u otra forma entre las partes implicadas.
Servidores
El servidor es el elemento encargado de ofrecer el servicio como tal, respondiendo a las peticiones del cliente. A medida que los clientes se hacen más complejos y presentan mayor número de funcionalidades, también los servidores deben ser capaces de proporcionar servicios más elaborados. Las capacidades fundamentales a las que responden los servidores dentro del ámbito SIG pueden dividirse en los siguientes grupos:
-
Servir representaciones de los datos
. Los servicios de cartografía Web, tanto en sus
orígenes como en la actualidad, son eminentemente
gráficos, y en última instancia lo que la aplicación Web
correspondiente va a hacer es mostrarnos algún tipo de
imagen con un mapa formado a partir de una serie de
datos geográficos.
El servidor puede responder directamente a este tipo de necesidades, preparando una imagen a partir de los datos geográficos de los que dispone. En el caso de que estos sean ya imágenes —por ejemplo, imágenes de satélite u ortofotos—, bastará servir estas, transmitiendo una versión escalada de las dimensiones exactas que el cliente necesite para representar en pantalla. En caso de que los datos sean de tipo vectorial, o bien ráster sin una forma de representación implícita —por ejemplo, un Modelo Digital del Terreno— es necesario emplear algún método para asignarles dicha representación. Este puede ser asignado por defecto por el servidor, que establecerá una simbología fija, o bien ofrecer un servicio más complejo en el que el cliente no solo pide una representación gráfica de una serie de datos para una zona dada, sino que además puede especificar cómo crear esa representación.
Asimismo, el servidor puede ofrecer la posibilidad de seleccionar los datos empleados para crear la representación gráfica. En términos de un SIG de escritorio esto es equivalente a seleccionar qué capas se van a representar de entre el total de las que se encuentran abiertas o bien en nuestro catálogo de datos al que tenemos acceso desde el SIG. En el caso de un servicio Web, el servidor dispone de una serie de capas a las que puede acceder, y a la hora de servir una imagen puede preparar esta usando unas u otras según las necesidades que el cliente especifique a la hora de hacer la petición del servicio. De igual modo, el orden en que se desea que las capas se pinten en el mapa también debe poder ser especificado por el cliente.
-
Servir los datos directamente
. Una opción más flexible que lo anterior es que el
servidor provea directamente los datos geográficos y sea
después el cliente quien los utilice como corresponda,
bien sea simplemente representándolos —en cuyo caso
debería ser el propio cliente quien establezca la
simbología, ya que esta tarea ya no queda en manos del
servidor— o bien trabajando con ellos de cualquier otra
forma, como por ejemplo analizándolos.
Aunque las posibilidades son mayores en este caso, se requieren por parte del cliente unas capacidades mayores, ya que mientras que representar una imagen es algo sumamente sencillo desde el punto de vista técnico, crear esta a partir de los datos geográficos es más complejo.
-
Servir consultas
. Un paso más allá en la funcionalidad que puede ofrecer
el servidor es responder a
preguntas
realizadas por el cliente relativas a los datos, ya sean
estas relativas a la parte espacial de dichos datos, o
bien a su componente temática. El servidor puede ofrecer
como respuesta conjuntos reducidos de los datos de los
que dispone, o valores que describan a estos. Estas
consultas pueden ser útiles, por ejemplo, para
establecer filtros previos cuando se dispone de un
conjunto amplio de orígenes de datos.
Un cliente Web puede obtener datos de distintos servidores, y puede consultar si, para un zona dada, estos servidores disponen de información, sin más que consultar la extensión cubierta por los datos de cada uno de ellos y comprobar si se interseca con la región de interés. En función de la respuesta, puede o no realizarse posteriormente el acceso a los datos en sí. Como ya vimos en el capítulo Metadatos , los metadatos son de gran utilidad para conseguir que este tipo de consultas se realicen de forma eficiente.
-
Servir procesos
. Por último, un servidor puede ofrecer nuevos datos,
espaciales o no espaciales, resultantes de algún tipo de
proceso o cálculo a partir de datos espaciales. En este
caso, el proceso constituye en sí el servicio ofrecido
por el servidor, y el cliente debe definir los
parámetros de entrada de este y los posibles parámetros
de ajuste que resulten necesarios. Los datos con los que
se trabaja pueden ser proporcionados por el cliente,
incorporándolos a su propia petición, o bien pueden
residir en el propio servidor. En este último caso, el
servidor ofrece tanto los datos, como la posibilidad de
extraer resultados a partir de ellos, es decir, los
datos y una herramienta para explotarlos. También pueden
emplearse datos en un servidor distinto, a los que el
servidor de procesos puede acceder si estos están
disponibles, convirtiéndose en cliente de ese segundo
servidor (Figura \ref{Fig:Datos_y_procesos_remotos}).
Las posibilidades que estos servicios brindan son muy numerosas. Por una parte, pueden añadirse funcionalidades avanzadas a interfaces Web, llevando a estas las capacidades propias de los SIG de escritorio. Por otra, la difusión de algoritmos de análisis geográfico resulta más sencilla, pudiendo ofrecerse estos a todo tipo de usuarios sin necesidad de ningún software especializado. Y por último, en ciertos casos pueden rebajarse los tiempos de proceso, ya que, en el caso de operaciones complejas, la mayor potencia del servidor respecto al cliente puede resultar en un mayor rendimiento. El reparto de tareas entre varios servidores (computación distribuida) es otra de las posibilidades que pueden a su vez ampliar la eficiencia de los procesos.

Esquema de acceso a un servicio de procesos remotos, el cual a su vez utiliza datos de un segundo servidor. El encadenamiento de procesos permite ampliar notablemente la utilidad de estos. $$\label{Fig:Datos_y_procesos_remotos}$$
Clientes
El cliente es el elemento que utiliza los datos proporcionados por el servicio. Para ello, realiza una petición a la que el servicio responde enviando dichos datos, que serán los que después se emplearán para realizar cualquier otra tarea, principalmente la representación de estos para que el usuario pueda visualizarlos. El cliente es, de este modo, el intermediario entre el usuario y los servicios y datos que el servidor ofrece.
Como hemos visto al estudiar los servidores, las principales capacidades de estos implican la transmisión de imágenes con cartografía ya elaborada, o bien directamente capas, ya sean de tipo ráster o vectoriales. En algunos casos, el servicio ofrecido es un servicio de procesos, pero su resultado generalmente es también una capa, por lo que, desde el punto de vista del cliente, la funcionalidad es en cierto modo similar (aunque internamente requiera una implementación por completo distinta).
El cliente, por tanto, debe disponer de capacidades para formular peticiones a servidores como los anteriormente descritos, así como para emplear las posibles respuestas que estos devolverán. Estas últimas capacidades incluyen por lo general componentes de representación, habitualmente con la forma típica de un visor en el que se permite cambiar la escala y desplazar la vista, tal y como ya vimos en el capítulo SIGs_escritorio . No obstante, pueden variar de un cliente a otro, desde el mínimo necesario para simplemente representar los datos obtenidos del servidor hasta conjuntos de funcionalidades mucho más avanzadas pensadas para un uso intensivo de esos mismos datos.
Distinguimos así dos tipos de clientes en función de las capacidades que tengan: clientes ligeros y clientes pesados .
Un cliente ligero es un programa de tamaño más o menos reducido, lo cual va consecuentemente asociado a unas capacidades limitadas. Hablamos de clientes ligeros cuando nos referimos a Web Mapping y a clientes que se ejecutan sobre un navegador Web, los cuales son siempre sencillos en cuanto a sus funcionalidades. En el momento de la carga de la página Web que contiene al cliente, el navegador descarga toda la lógica del programa, lo cual hace necesario limitar el tamaño de este. No obstante, los clientes Web empiezan progresivamente a ampliar sus posibilidades, y en ello juegan un importante papel otros servicios distintos a los de mapas o los de datos, como pueden ser los de procesos. Estos permiten que las funcionalidades adicionales no se implementen en el propio cliente (y por tanto sin aumentar en exceso su tamaño y sin disminuir su «ligereza»), sino que se accede a estas también como servicios remotos. La evolución de la cartografía Web en esta dirección se dirige desde el Web Mapping al Web GIS , tal y como comentamos algunas páginas atrás. A diferencia del cliente ligero, el cliente pesado es una aplicación individual que no se ejecuta sobre otra aplicación soporte como puede ser un navegador Web. Al ser un programa independiente, debe ocuparse de toda la lógica del proceso y de proveer todas las funcionalidades necesarias, por lo que su tamaño es generalmente mayor.
Pese a ello, un cliente pesado no ha de ser necesariamente más potente y con más funcionalidades que uno ligero (aunque habitualmente lo es), ya que existen aplicaciones muy sencillas con capacidad para conectarse a servicios de mapas, que ofrecen poco más que un visor de cartografía. La diferencia no estriba en las capacidades del programa, sino en el enfoque a la hora de implementar este y el uso o no de otra aplicación «plataforma», generalmente en forma de un navegador Web. Los clientes pesados suelen permitir el uso de datos no procedentes directamente del acceso a servicios, tales como datos en ficheros locales, y no están pensados exclusivamente como clientes, sino como aplicaciones más amplias que además disponen de capacidades para aprovechar un determinado tipo de servicios.
Dicho de otro modo, un cliente pesado tal y como un SIG de escritorio tiene utilidad aunque no se emplee como cliente de ningún servicio y no se disponga de conexión a red alguna, ya que puede alimentarse con datos locales, y todas sus restantes funcionalidades (análisis, preparación de cartografía, etc.) pueden aprovecharse con dichos datos.
Limitaciones y problemas de la cartografía Web
Trasladar las ideas de los SIG de escritorio a la Web no es sencillo, por cuanto el entorno en el que nos movemos es muy distinto en uno u otro caso. La Web tiene sus propias limitaciones e inconvenientes, que en muchos casos no existen en el caso de una aplicación de escritorio, y este hecho presenta dificultades complejas de salvar, obligando a desarrollar soluciones alternativas.
Una limitación básica es la impuesta por el propio navegador como marco de trabajo. Las propias ventajas que este aporta son también responsables de ciertas limitaciones, ya que en el desarrollo de una aplicación SIG Web no se tiene la misma libertad que al desarrollar una aplicación de escritorio. Este no es un problema exclusivo del Web Mapping , sino en general de todas las aplicaciones Web. Pese a los avances que han tenido lugar en este sentido y la rápido evolución de las tecnologías Web, siguen sin poder ofrecer exactamente las mismas funcionalidades en lo que a interfaces respecta.
A lo anterior debemos sumar el hecho de que las tecnologías Web en general son recientes y en cierto modo inmaduras, y aunque se emplea gran cantidad de medios y esfuerzo en el ámbito Web debido a su vital importancia en la actualidad, una buena parte de los elementos tecnológicos sobre los que se fundamenta el Web Mapping actual no están todavía completamente desarrollados y necesitan aún evolucionar.
El aspecto más problemático es, no obstante, la propia red, especialmente en lo que respecta a su fiabilidad y rendimiento. Todos los datos que el cliente emplea en una aplicación de cartografía Web provienen de la red, y por tanto existe una fuerte dependencia entre la aplicación y el funcionamiento tanto de esta como del servidor que a través de ella nos proporciona esos datos.
Si abrimos un archivo con datos espaciales en nuestro ordenador desde un SIG de escritorio, podemos casi garantizar que esa misma operación funcionará de igual modo si la repetimos en otro momento. Tener esa misma seguridad cuando se trabaja con datos remotos no es tan sencillo, ya que la red puede no funcionar o el servidor puede estar recibiendo en este momento gran cantidad de peticiones de otros clientes y no ser capaz de gestionarlas eficientemente y ofrecernos al instante respuesta a nuestra petición. En definitiva, las mismas circunstancias que afectan a todas las aplicaciones Web y que son conocidas por todos.
El rendimiento de la red es más importante aún si cabe en el caso de trabajar con información geográfica, ya que los datos suelen ser voluminosos. Visualizar un mapa y que este pueda desplazarse y modificarse de forma igual de fluida que al trabajar con una aplicación de escritorio requiere por un lado un ancho de banda suficiente para transmitir la gran cantidad de datos necesarios, y por otro la implementación de algunas técnicas particulares que facilitan este proceso. Por su importancia, veremos en detalle las técnicas de tiling (división horizontal de los datos geográficos en teselas) y cacheo (almacenamiento temporal de datos en la máquina del cliente), utilizadas habitualmente en la actualidad.
Tiling y cacheo
Dos técnicas básicas que se emplean actualmente en los clientes Web que manejan información geográfica son el tiling y el cacheo . Estas técnicas permiten que la experiencia de trabajar con información geográfica dentro de una aplicación SIG Web sea más agradable, logrando una mayor fluidez y superando en cierta medida las limitaciones de la red. Aunque es cierto que cada vez disfrutamos de mayores anchos de banda y velocidades de transmisión más altas, también aumentan de igual modo los volúmenes de datos manejados, con lo que las dificultades siguen existiendo de manera similar.
El tiling es una técnica consistente en dividir las imágenes con las que se trabaja en imágenes menores que formen un mosaico. Esto permite un trabajo más rápido, al utilizar unidades mínimas de menor tamaño y poder reducir la necesidad de transmitir datos a través de la red si se realiza una gestión correcta del conjunto de elementos de ese mosaico.
Esta división es similar en forma a la propia que se da en los datos originales, ya que, como sabemos (véase sección divisionHorizontal ), estos también se encuentran divididos horizontalmente. No obstante, se trata de una estrategia propia del sistema cliente-servidor, que divide las propias imágenes que luego se representarán en este último, de forma que en lugar de transmitir una única imagen se transmiten varias de menor tamaño y la información correspondiente a la posición relativa de estas.
El cacheo , por su parte, es una técnica no exclusiva del ámbito SIG, sino de la Web en general, y consiste en almacenar de forma temporal los datos obtenidos de un servidor en la máquina local o bien en una máquina intermedia ( proxy ). De este modo, si volviera a resultar necesario acceder a esos datos, no han de pedirse al servidor, sino que pueden recuperarse de la copia local, con las ventajas que ello tiene en cuanto a la velocidad de acceso y la fiabilidad del proceso.
El uso conjunto de tiling y cacheo puede disminuir sensiblemente el volumen de datos a transmitir para, por ejemplo, modificar el encuadre de un mapa en una aplicación SIG Web. La figura \ref{Fig:Tiling} muestra un ejemplo sencillo que servirá para comprender el ahorro de datos que puede conseguirse con el uso conjunto de estas técnicas.
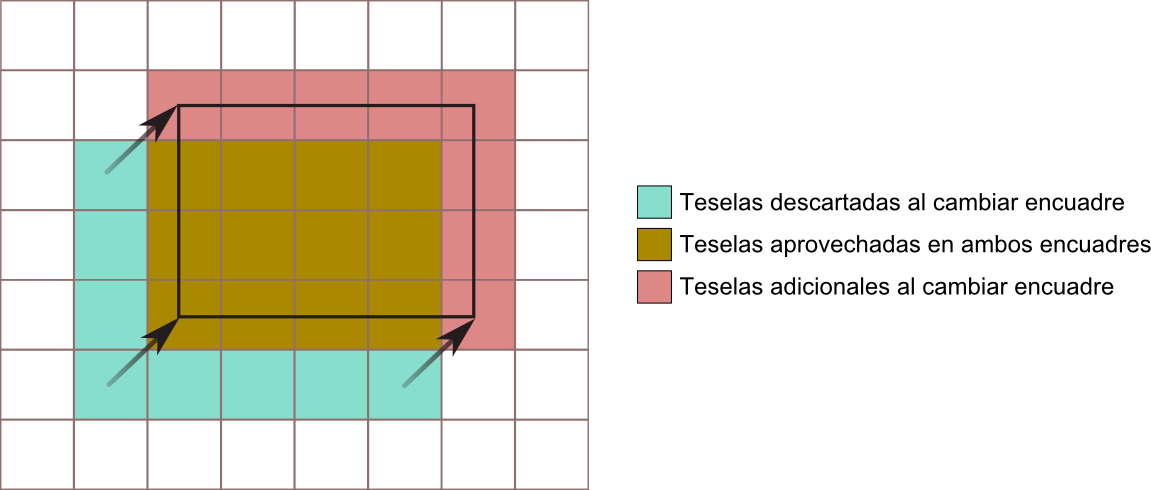
En la figura puede verse el dato global al que se accede, dividido en una serie de unidades. Ello no quiere decir que el dato original tenga ese número de divisiones o que existan otros tantos ficheros. Puede tratarse de un único fichero, o de un número muy elevado de ellos. Las divisiones se realizan a efectos de crear el mosaico de imágenes a la hora de transmitir estas.
Inicialmente, la aplicación Web encuadra una región que cubre 20 elementos o teselas. Si el usuario desplaza el encuadre para que cubra otro área distinta, como en el caso mostrado en la figura, el cliente realizará una nueva petición y obtendrá una nueva imagen, que tendrá exactamente el tamaño con que esa imagen va a representarse. Este es exactamente el mismo tamaño que la imagen que encontramos inicialmente en el encuadre original, y por tanto la representación de este encuadre original y posteriormente el encuadre modificado requiere transmitir dos imágenes que cubren cada una de ellas veinte teselas.
Si, por el contrario, aplicamos conjuntamente las técnicas anteriores de tiling y cacheo , al variar el encuadre no es necesario obtener del servidor una imagen que cubra todo el área a representar, sino tan solo los 8 elementos correspondientes a la zona no cubierta por la imagen inicial, ya que los restantes ya habrán sido obtenidos con anterioridad y se encontrarán almacenados ( cacheados ) en nuestro ordenador. Es decir, el cliente crea la imagen a representar con 8 subimágenes pedidas al servidor y otras 12 ya descargadas previamente, reduciendo sensiblemente el volumen de datos pedidos al servidor.
Cuando este esquema de funcionamiento se combina con otras tecnologías Web que añaden a su vez mayor fluidez y una mejor respuesta de la aplicación, el resultado es una aplicación SIG altamente funcional, cuyo comportamiento se asemeja en cuanto a rendimiento al de un SIG de escritorio trabajando con datos locales.
Este tipo de técnicas no son exclusivas de los SIG en Internet, sino que también se aplican por igual al caso de SIG de escritorio cuando estos actúan como clientes y acceden a datos remotos.
La combinación de tiling y cacheo se lleva a cabo a múltiples escalas, de forma que se reduce el número de operaciones a realizar y se obtiene un mayor rendimiento. Se emplean las denominadas pirámides , que ya vimos en el apartado Generalizacion_en_SIG dedicado a la generalización cartográfica en un SIG. Estas pueden ser empleadas también en el lado del servidor, incluso cuando este sirve mapas creados a partir de cartografía vectorial. Para evitar tener que rasterizar los datos vectoriales cada vez que se realiza una petición (lo cual supondría un gran coste en términos de proceso), se rasterizan de antemano a distintas escalas, y se cachean en el servidor. De esta forma, cuando el cliente efectúa la petición, ya se dispone de una imagen que servirle, sea cual sea la escala que pida..
Una técnica de reciente aparición es la denominada tiling vectorial . Aplicando los mismos principios que el tiling , es decir, la subdivision de los datos de forma regular, las capas vectoriales se «trocean» en el origen y se envían después solamente los datos necesarios para el área cubierta en el cliente. Combinando este enfoque con el uso de capas con distinto detalle según la escala, se logran dos ventajas:
- Disminución del volumen de datos.
- Capacidad de modificar la simbología en el cliente.
Al enviar los datos en lugar de una representación de estos, el cliente es quien debe establecer la simbología, lo cual permite que sea el usuario quien seleccione cómo representar los elementos vectoriales. Al mismo tiempo, se logran ventajas en la experiencia de usuario, debidas principalmente a la escalabilidad de los datos vectoriales, que permite por ejemplo presentar transiciones más fluidas cuando se modifica la escala del mapa.
Estándares
Para garantizar el buen funcionamiento de un sistema cliente-servidor, es importante definir de forma adecuada cómo se establece la comunicación entre clientes y servidores, de forma que estos primeros no solo puedan obtener los propios datos geográficos de estos últimos, sino también realizar consultas o conocer qué otras funcionalidades se encuentran disponibles.
En otras palabras, resulta necesario definir una lingua franca para que todas las comunicaciones se produzcan de forma fluida. Esto obliga a establecer una cierta normalización y crear elementos estandarizados que sean conocidos e implementados por las distintas partes, y hacerlo para cada uno de los servicios ofrecidos, así como para los propios datos. Esta lingua franca es lo que denominamos un estándar .
El modelo de cliente-servidor en términos tecnológicos no es muy diferente de la idea de un cliente y un proveedor de servicios en la vida real. Una persona (el cliente) que quiera adquirir un producto de un distribuidor (el servidor) debe igualmente comunicarse con él para preguntarle si dispone del producto deseado, realizar una petición de este y después recibirlo cuando el distribuidor se lo envíe.
Imaginemos ahora la situación en la que una persona en España desea adquirir un producto electrónico de un proveedor chino. En primer lugar, es probable que tenga dificultades para entender el catálogo de productos, pues este describirá cada uno de ellos en chino. Si consigue localizarlo y desea adquirirlo, es igualmente probable que encuentre dificultades para comunicárselo al proveedor, ya que seguirá existiendo la misma barrera lingüística. Y si finalmente recibe el producto, puede tener dificultades al utilizarlo, ya que este puede funcionar a un voltaje distinto al de la red eléctrica española o bien estar preparado para un tipo de enchufe distinto.
Este pequeño ejemplo nos hace ver que en la relación cliente-servidor pueden surgir problemas derivados de la falta de elementos comunes entre ambos actores. Si todos los elementos que toman parte en el establecimiento de esa relación comercial estuvieran normalizados y fueran únicos, un comprador de cualquier parte del mundo podría de forma inmediata comprar un dispositivo a cualquier vendedor de otro país comunicándose en un único idioma, y tener después la garantía de poder usarlo sin problemas.
En el ámbito de la información geográfica la situación es similar a la anterior. Hay muchos formatos distintos para almacenarla y muchas formas distintas de transmitirla, y ello dificulta el trabajo. Igual que los clientes españoles no hablan el mismo idioma que los vendedores chinos, no todos los clientes SIG hablan el mismo idioma que todos los servidores, y dos cualesquiera de ellos no han de «entenderse» necesariamente.
De hecho, históricamente los distintos fabricantes de clientes definían por sí mismos la forma en que sus programas se comunicaban, que no coincidía con la del resto de fabricantes. Un cliente de un fabricante dado no podría acceder a los servicios de un servidor creado por un fabricante distinto. Este paradigma, característico del software privativo, es un problema, pues dificulta el acceso a los datos.
En circunstancias ideales, debe existir una total interoperabilidad con independencia de los formatos y las aplicaciones empleadas, pudiendo interactuar entre sí los distintos clientes y servidores. Los estándares son el elemento que va a permitir esa interoperabilidad, definiendo el marco común que clientes y servidores emplearán para entenderse. En un contexto altamente heterogéneo tanto en datos como en herramientas, lograr esto no resulta una tarea sencilla[ Lemmenes2006IEEE ], y los estándares son los encargados de aportar homogeneidad tecnológica.
Estándares abiertos e interoperabilidad
La interoperabilidad implica que podemos sustituir unos elementos del sistema en el que se incluyen los clientes y servidores por otros distintos, teniendo la seguridad de que van a interaccionar entre ellos sin dificultades. Las funcionalidades que un cliente o servidor nos ofrece pueden ser distintas a las de otro, pero independientemente de su origen (independientemente del fabricante), si esos elementos implementan un estándar dado, siempre podrán interactuar con todos aquellos que también lo implementen.
La clave, por tanto, está en los estándares, y en particular en que estos sean estándares abiertos . Un estándar es un documento o práctica que busca armonizar los aspectos técnicos de un producto o servicio.
Un estándar se considera como tal cuando es empleado por un grupo o comunidad, que lo acepta para la definición de las características de ese producto o servicio en su seno. Si únicamente es el uso del estándar el que lo ratifica como tal, se denomina estándar de facto . El formato shapefile para capas vectoriales, por ejemplo, es uno de estos estándares, ya que está ampliamente difundido y existe tal cantidad de datos en este formato que todas las aplicaciones deben implementarlo para tener valor práctico.
Existen estándares que se convierten en normas o estándares de iure , cuando estos son promovidos por algún organismo oficial de normalización o su uso se impone con carácter legal.
Un estándar abierto es aquel cuya definición se encuentra disponible y todo aquel que lo desee puede conocerla y emplearla para el desarrollo de la actividad relacionada con ese estándar. En nuestro campo de trabajo, eso quiere decir que cualquier desarrollador que desee crear un nuevo cliente o servidor para datos SIG puede acceder al estándar y desarrollar en base a este.
Los principios fundamentales de los estándares abiertos son los siguientes:
- Disponibilidad . Los estándares abiertos están disponibles para todos el mundo para su lectura y uso en cualquier implementación.
- Máxima posibilidad de elección para los usuarios finales . Los estándares abiertos crean un mercado competitivo y justo, y no bloquean a los usuarios en el entorno de un vendedor particular. Desde el punto de vista de quienes venden la tecnología SIG, esto no es tan ventajoso, ya que permite la aparición de competidores que antes no podían existir. Si un fabricante basa sus productos en un estándar cerrado definido por él mismo, otros no pueden elaborar soluciones que trabajen con esos productos, ya que no conocen el estándar empleado. Asimismo, el fabricante puede, por ejemplo, cambiar el estándar utilizado por su producto de servidor, y obligar a los consumidores y a todo aquel que quiera utilizar un servicio basado en ese servidor a que actualicen también los clientes, pues los anteriores ya no podrán comunicarse con el nuevo servidor. Utilizando estándares abiertos, la competencia entre fabricantes ha de basarse puramente en las capacidades que ofrecen, con lo que los consumidores ganan en calidad de los productos y en posibilidades de elección.
- Gratuidad . Implementar un estándar es gratuito, sin necesidad de pagar, como en el caso de una patente. Los organismos que generan los estándares pueden cobrar una cierta cantidad por acceder a la definición de los estándares, con objeto de financiar así la labor que desarrollan, y también pueden cobrar por emitir certificados de que un determinado producto o servicio se ha desarrollado de acuerdo con el estándar.
- Discriminación . Los estándares abiertos y las organizaciones que los desarrollan no favorecen de ningún modo a uno u otro implementador sobre los restantes.
- Extensión o creación de subconjuntos de un estándar . Los estándares abiertos pueden extenderse o bien presentarse como subconjuntos del estándar original.
- Prácticas predatorias . Los estándares abiertos pueden tener licencias que requieran a todo aquel que desarrolle una extensión de dicho estándar la publicación de información acerca de esa extensión, y el establecimiento de una licencia dada para todos aquellos que creen, distribuyan y vendan software compatible con ella. Un estándar abierto no puede prohibir de otro modo el desarrollo de extensiones.
Para tener una noción de lo que en la práctica realmente significa el uso de estándares abiertos en el campo de los SIG, podemos ver la figura \ref{Fig:Esquema_no_interoperable}, donde se representa el esquema de una arquitectura no interoperable. Es decir, una arquitectura que no se basa en este tipo de estándares.
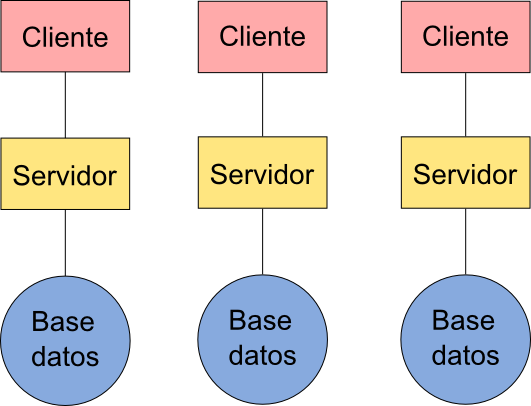
Los datos que se encuentran en cada base de datos son accesibles únicamente a través de un único cliente, que es aquel correspondiente al servidor que ofrece servicios basados en esos datos. Los restantes datos quedan fuera del alcance de ese cliente, ya que no es capaz de acceder a ellos. Las diferentes soluciones cliente-servidor crean en esta situación un conjunto de islas tecnológicas, cada una completamente independiente y sin posibilidad alguna de interactuar con las restantes.
Entre los principales inconvenientes de una arquitectura no interoperable como la representada podemos citar los siguientes:
- Desperdicio de recursos . Cada servicio debe gestionar sus propio conjunto de datos, lo cual requiere abundantes recursos y no es sencillo, además de implicar un elevado coste.
- Necesidad de conocer múltiples clientes . Si para acceder a cada servicio necesitamos su cliente particular, acceder al conjunto de servicios ofrecidos por esos servidores requiere por parte de los usuarios aprender a utilizar tantos clientes como servidores existan.
- Imposibilidad de combinar datos . Dos datos a los que pueda accederse a través de dos servidores distintos no podrán utilizarse simultáneamente en un único cliente, ya que este no podrá comunicarse con ambos servidores. Un análisis que requiera distintos tipos de datos no podrá realizarse si todos ellos no se ofrecen a través de un mismo servidor.
- Imposibilidad de combinar funcionalidades . Los datos ofrecidos por un servidor pueden usarse para el desarrollo de muchas tareas. Estas tareas requieren que las correspondientes herramientas estén disponibles en los clientes, y estos se diferencian notablemente, de la misma forma que lo hacen también los SIG de escritorio entre sí. Si acceder a los datos a través de un servidor solo se puede hacer empleando un cliente concreto, no existe la posibilidad de aprovechar las funcionalidades de otro cliente sobre esos mismos datos, y el usuario ve así limitadas sus posibilidades de trabajo.
En contraste con lo anterior, tenemos una situación de plena interoperabilidad basada en estándares abiertos como la representada en el esquema de la figura \ref{Fig:Esquema_interoperable}.
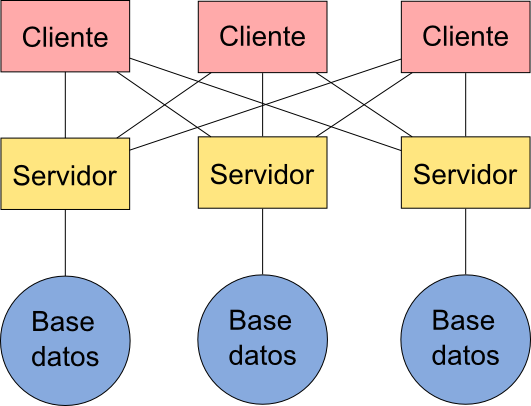
En este caso, existe un servidor que es el que gestiona y ofrece los servicios para cada base de datos, pero a él pueden acceder todos los clientes, ya que por el hecho de estar basados en estándares abiertos es posible una comunicación plena entre dos cualesquiera de ellos.
En esta situación, un usuario puede emplear su cliente favorito (siempre que este implemente los estándares pertinentes) para acceder a muchos servicios distintos, o bien puede utilizar varios clientes para acceder a unos mismos datos, eligiendo en cada momento el que más le convenga según sus necesidades. Las posibilidades de trabajo se multiplican cuando la arquitectura del sistema se fundamenta en estándares abiertos.
Las ventajas no son solo para los usuarios, sino también para los desarrolladores. A la hora de crear un cliente, no es necesario comprobar que este se comunica bien con todos los servidores y funciona correctamente, sino simplemente seguir las especificaciones del estándar. Todo aquel servidor que las implemente funcionará sin dificultades, ya que el estándar garantiza la buena comunicación y la interoperabilidad.
Entidades creadoras de estándares
Crear un estándar no es una labor sencilla. Se han de recoger las principales necesidades y armonizar todas ellas en una especificación única, de modo que clientes y servidores que implementen ese estándar sean de la mayor utilidad posible para todos los usuarios.
Existen organizaciones dedicadas a redactar las especificaciones correspondientes a estándares que cubran los distintos servicios, así como a promoverlas y mejorarlas. Los estándares más habituales en el campo de la información geográfica son elaborados por tres organizaciones: el Open Geospatial Consortium (OGC), ISO y W3C.
Open Geospatial Consortium (OGC)
El Open Geospatial Consortium es una organización internacional y voluntaria dedicada a la elaboración de estándares. En el OGC participan más de 350 organizaciones miembro, incluyendo entre ellas a los principales fabricantes del sector, agencias nacionales, grupos de investigación u organizaciones sin ánimo de lucro, entre otros. Estas organizaciones miembro colaboran para alcanzar consensos y desarrollar e implementar estándares en el ámbito de los contenidos geoespaciales.
Algunos de los estándares OGC más relevantes, los cuales veremos a lo largo de este capítulo, son los siguientes:
- WMS . Para obtener imágenes de mapas.
- WCS . Para obtener y consultar coberturas.
- WFS . Para obtener y editar entidades geográficas y sus atributos asociados.
- WPS . Para servicios de procesos remotos.
- GML . Para almacenamiento de información geográfica.
- CSW . Para consultas en catálogos.
Cada uno de estos estándares está descrito en una especificación, y estas están sujetas a cambios y mejoras, existiendo varias versiones en cada caso.
ISO
ISO es una organización internacional dedicada a la elaboración de estándares no solo en el ámbito geográfico, sino en todas las áreas. ISO es responsable, por ejemplo, de estándares bien conocidos y aplicados en la industria actual, tales como los relacionados con la gestión medioambiental en empresas o los estándares de calidad.
Dentro de ISO existen diversos comités técnicos, cada uno de los cuales se encarga de definir los estándares correspondientes a un campo de trabajo. El comité ISO/TC 211 es el responsable de aquellos relacionados con la información geográfica digital.
ISO redacta Especificaciones Técnicas y Estándares Internacionales, catalogando estos con un número que los identifica. Los elaborados por ISO/TC 211 corresponde a la serie 19100.
Existe una estrecha relación entre ISO y OGC, y los estándares elaborados por ambas organizaciones son muchos de ellos muy similares o incluso idénticos. De hecho, algunos de los estándares desarrollados por el OGC, como WMS o GML, citados anteriormente y que en breve detallaremos, son también estándares ISO.
W3C
El Consorcio World Wide Web (W3C) es un consorcio internacional donde las organizaciones miembro, personal a tiempo completo y el público en general, trabajan conjuntamente para desarrollar estándares Web. Según su propia definición, la misión del W3C es «guiar la Web hacia su máximo potencial a través del desarrollo de protocolos y pautas que aseguren el crecimiento futuro de la Web».
El W3C no guarda una relación directa con los SIG, pero parece lógico pensar que todo aquello que se haga en el seno de Internet debería acomodarse a las pautas establecidas por este consorcio, en especial si lo que se desea es maximizar la interoperabilidad, como ya hemos visto que resulta de interés en el ámbito SIG. Puesto que la mayoría de los estándares abiertos que vamos a ver en este capítulo se aplican sobre tecnologías que operan en la red, estos se han de fundamentar siempre que sea posible en otros existentes desarrollados por el W3C, o al menos seguir las recomendaciones de este organismo.
Visto de otro modo, el W3C persigue objetivos similares a los de las organizaciones que elaboran estándares para la información geoespacial, pero su campo de actuación es la red en términos generales.
De entre todos los elementos definidos por el W3C, resulta de especial importancia el lenguaje XML (eXtensible Markup Language). XML no es un lenguaje en sí, sino que permite definir la gramática de otros lenguajes. Es lo que se conoce como metalenguaje . De este modo, puede utilizarse para definir reglas para crear formas de expresión que permitan recoger cualquier tipo de información. Esto hace que pueda emplearse para el intercambio de información de toda clase, y es la base de la mayoría de estándares a tratar en este apartado.
Estándares para representación y obtención de información geográfica
Entre los estándares más importantes encontramos aquellos que especifican la forma de recoger la información geográfica, así como aquellos que definen el modo en que esta se transmite.
Los siguientes estándares OGC forman parte de este grupo.
Simple Features for SQL (SFS)
Sabemos del capítulo Consultas que el lenguaje SQL en su forma básica no sirve para recoger las geometrías que forman la parte espacial de una entidad, sino únicamente los datos no espaciales de esta. Sin embargo, versiones posteriores de SQL permiten la definición de tipos personalizados, y esto puede emplearse para poder incorporar estos elementos espaciales dentro del lenguaje.
El problema que nos encontramos en este caso es que, debido a que la propia flexibilidad de este mecanismo, los tipos pueden implementarse de diversas formas, lo cual no favorece la interoperabilidad. Si una consulta se establece sobre unos tipos definidos de forma distinta a como lo están en la base de datos que recibe la consulta, esa consulta no podrá procesarse correctamente. Es necesario definir una forma estandarizada de definir esos tipos, y una pauta a seguir para su implementación.
OGC define la especificación Simple Features for SQL (SFS) con objeto de hacer frente al problema anterior. SFS define por un lado unos tipos estandarizados para geometrías, los cuales se basan en otra especificación OGC denominada OpenGIS Geometry Model , que establece una forma de definir geometrías. Por otra parte, se definen una serie de operaciones SQL que operan sobre esos tipos.
Todas las geometrías que pueden definirse según este esquema son geometrías en un espacio bidimensional, y cada objeto geométrico está asociado a un sistema de referencia en el cual se define.
Existe un objeto fundamental denominado Geometry del que heredan los restantes en una jerarquía bien definida. Los métodos de este objeto son de tres tipos:
- Métodos básicos. Proveen información sobre el objeto (dimensión, tipo de geometría, sistema de referencia, etc.)
- Métodos para comprobar relaciones espaciales entre objetos geométricos (cruza a, contiene a, se intersecta con, etc.)
- Métodos que efectúan algún tipo de análisis (unión de geometrías, distancia entre geometrías, área de influencia de una geometría, etc.)
Cada uno de los objetos derivados de la clase raíz Geometry tiene además a su vez sus propios métodos específicos, siempre dentro de alguno de los grupos anteriores.
Con estos objetos y sus métodos se da respuesta a todas las necesidades que aparecen en la realización de consultas sobre bases de datos espaciales. La especificación SFS permite así dotar de potencia al lenguaje de consulta SQL y hacerlo de forma estandarizada para ampliar la interoperabilidad en las operaciones de consulta.
Geography Markup Language (GML)
El Geography Markup Language (GML) es un lenguaje basado en XML, diseñado para el almacenamiento de información geográfica. Utilizando este lenguaje, resulta posible el intercambio de información geográfica de forma interoperable.
GML puede utilizarse para transmitir información a través de una red, como parte de un servicio. Este es el caso del servicio WFS que veremos más adelante, que devuelve información geográfica codificada según este lenguaje. No obstante, puede emplearse igualmente para almacenar la información con la que trabajamos de un SIG, del mismo modo que utilizamos cualquiera de los formatos de archivo que vimos en el capítulo Fuentes_datos . Es decir, sin que tengan que mediar servicios en ningún momento.
Algunos SIG permiten este uso, y soportan GML como un formato más de archivo. No obstante, no es una práctica común, ya que, pese a las ventajas de ser un estándar aceptado, GML es un formato de fichero de tipo texto (está basado en XML) y produce archivos de gran tamaño. Para este uso, es más habitual recurrir a algún otro formato.
GML es un lenguaje extremadamente genérico, que permite recoger tanto datos ráster como vectoriales y hacerlo con mucha flexibilidad. Permite, por ejemplo, recoger datos vectoriales sin que exista una geometría asociada, es decir, simplemente almacenando unos atributos como si se tratara de una base de datos no espacial. Esta gran flexibilidad, que es uno de los puntos fuertes de GML, es también uno de sus inconvenientes, ya que la especificación es muy compleja y difícil de implementar en su totalidad.
La versión más reciente de GML es GML3.
Existe un dialecto conocido como Simple Features Protocol que trata de solucionar el problema de la excesiva complejidad de GML3.
Web Feature Service (WFS)
El servicio Web Feature Service WFS está relacionado con los datos de tipo vectorial, y a través de él se sirven directamente las entidades de un dato vectorial con sus geometrías y datos alfanuméricos asociados. Desde este punto de vista, acceder a un servicio WFS es similar a acceder a una capa vectorial cualquiera o a una base de datos, ya que el SIG puede recuperar la información correspondiente (tanto la componente geográfica como la temática de cada entidad) y operar con ella.
En particular, las operaciones que permite un servicio WFS son:
- Crear una nueva entidad.
- Borrar una entidad.
- Actualizar una entidad.
- Obtener o consultar el conjunto de entidades en base a condiciones espaciales y no espaciales.
Distinguimos dos tipos de servicios WFS:
- Un servicio WFS básico, que solo permite consultar los datos, pero no modificarlos.
- Un servicio WFS transaccional (WFS-T), que permite realizar modificaciones en las entidades.
La versión más actual de la especificación WFS es la 1.1. No obstante, la versión 1.0 es la implementada mayoritariamente en los servidores actuales. WFS 1.1 utiliza GML3 como lenguaje para la codificación de la información a servir, mientras que WFS 1.0 usa GML2.
Filter Encoding
Cuando un cliente efectúa una petición a un servidor WFS, no es necesario que obtenga de este todas las entidades de una capa. Incluso para una zona geográfica dada, el usuario puede querer obtener a través del cliente solo aquellas entidades que cumplan un criterio dado.
Ya conocemos elementos que permiten realizar ese tipo de consultas para trabajar con un subgrupo de las entidades de una capa. En el capítulo Consultas vimos el lenguaje SQL, mediante el cual podían definirse consultas de esta clase.
El estándar Filter Encoding define un formato basado en XML para el almacenamiento de expresiones de filtrado según otro estándar OGC conocido como OGC Common Catalog Query Language . La expresión del filtro expresada según la especificación Filter Encoding puede ser validada y procesada por herramientas adicionales para convertirla en las expresiones correspondientes en otro lenguaje para consulta de bases de datos espaciales. Por ejemplo, en una clausula WHERE de SQL que emplear en una sentencia SELECT .
Las expresiones que pueden recogerse empleando Feature Encoding pueden ser consultas con componente espacial o hacer referencia a la parte temática de la información geográfica. Es decir, que permiten recoger toda la variabilidad de las consultas espaciales que vimos en el capítulo Consultas
Además de emplear estas expresiones para consultar servicios WFS, pueden utilizarse igualmente para otros como los servicios de Nomenclátor (Gazetteer) que veremos más adelante, y en general en todos aquellos en los que tenga sentido especificar algún tipo de restricción a la hora de realizar una petición al servidor.
Web Coverage Service (WCS)
Si el estándar WFS permite obtener de un servidor datos vectoriales en forma de entidades, el estándar Web Coverage Service hace lo propio con datos ráster. Este servicio está pensado para tratar con coberturas , es decir, representaciones de un fenómeno que varía en el espacio. Como ya vimos en su momento, las coberturas se corresponden con el modelos de campos.
Representar una cobertura puede hacerse de muchas formas distintas: capas ráster, Redes de Triángulos Irregulares (TIN) o funciones matemáticas. No obstante, por el momento el estándar WCS solo está preparado para el trabajo con mallas ráster regulares.
EL servicio WCS ofrece los datos de la capa ráster como tales, con su semántica original. Es decir, que un servicio WCS puede servir un MDE y el cliente obtiene directamente los valores de elevación en sus unidades correspondientes.
Estándares para mapas y visualización
De entre todos los estándares que vamos a ver en esta sección, los más importantes por ser los más extendidos son los que sirven mapas. Entendemos por mapa en este contexto a una representación gráfica de una determinada información geográfica, elaborada a partir de una o más capas.
Gran parte de los sitios Web que ofrecen información geográfica lo hacen en forma de mapas, es decir, que permiten simplemente «ver» los datos geográficos, y los estándares de esta sección son los encargados de definir ese tipo de servicios.
El estándar WMS, el principal en esta categoría, está ampliamente probado e implementado en gran cantidad de software, y es el soporte fundamental para cientos de aplicaciones basadas en mapas, lo que ratifica su utilidad y validez.
Web Map Service (WMS)
El estándar Web Map Service (WMS) define los elementos necesarios para un servicio de mapas.
Un servicio WMS devuelve una imagen con información geográfica, pero esta solo contiene la propia información visual para que el cliente pueda mostrarla. Es decir, si se pide a este servicio un mapa creado a partir de un MDE, la información de los píxeles no contiene la elevación de la coordenada correspondiente, sino el color asociado en función de un determinado criterio. La imagen puede contener otros elementos visuales tales como etiquetas o símbolos, en función de cómo se haga la representación en el servidor. Una vez que el cliente recibe la imagen, no puede actuar sobre esta para cambiar la forma de representación de una capa, sino simplemente representarla como es.
En un servicio WMS, cuando el cliente pide un mapa al servidor, puede controlar en cierto modo la forma en que este va a representarlo (colores, estilos, etc.). El servidor ofrece una serie de opciones predeterminadas, de las cuales el cliente solo conoce su nombre, y puede elegir una de ellas. No obstante, no puede saber exactamente qué caracteriza a cada uno de esos perfiles predeterminados de representación ni tampoco puede definir los suyos propios.
Para solucionar esto y ampliar las capacidades del servicio WMS, aparece otro nuevo estándar: SLD.
Styled Layer Description (SLD)
El estándar OGC Styled Layer Description (SLD) define una forma de almacenar los parámetros de representación empleados para crear un mapa a partir de los datos geográficos. Este estándar permite extender las capacidades de WMS, ofreciendo al cliente la posibilidad de definir sus propias configuraciones.
SLD es un estándar complejo que permite cubrir situaciones variadas y no solo las más sencillas y habituales. Permite, por ejemplo, el ajuste de elementos tales como etiquetas o simbologías personalizadas para elementos puntuales (por ejemplo, representar cada punto de una capa de localizaciones de estaciones de autobús con un pequeño dibujo de un autobús), Para esto último se apoya en otros estándares tales como SVG, diseñado para la representación de gráficos vectoriales.
Las simbologías recogidas en un documento SLD pueden emplearse para la representación tanto de capas ráster como vectoriales.
A la hora de definir una simbología para una capa, es necesario conocer cierta información acerca de esta. Para definir una simbología sencilla en la que todos los elementos de una capa van a ser representados de igual forma (por ejemplo, todos las líneas de una capa de ríos con un grosor dado y en color azul), esta información no es imprescindible, pero en caso de que se quiera variar ese color o ese grosor en función de un atributo, será necesario conocer qué atributos tiene la capa y de qué tipo son.
Para hacer esto, pueden emplearse las operaciones de los servicios de donde se toman los datos a representar. La operación DescribeLayers del servicio WFS permite conocer los tipos de entidades de una capa representada. La información sobre los atributos puede obtenerse con la operación DescribeFeatureTypes .
Web Mapping Context (WMC)
El estándar Web Mapping Context (WMC) define un formato estandarizado para almacenar un contexto . Un contexto recoge la información necesaria para reproducir las condiciones de una determinada sesión de uso de un cliente, de tal forma que ese cliente pueda restablecerlas posteriormente. El contexto se almacena en un archivo XML.
En el contexto se almacena información sobre las capas que forman el mapa representado por el cliente y los servidores de los que estas se obtienen, la región cubierta por el mapa, así como información adicional para anotar este mapa.
Los usos que se le pueden dar a un contexto son variados, entre ellos los siguientes:
- Mediante un contexto se puede definir una configuración particular de inicio para distintos tipos de usuario del cliente.
- Un contexto puede emplearse para almacenar el estado del cliente a medida que el usuario navega y modifica elementos, pudiendo retornar a una configuración establecida anteriormente.
- El contexto puede almacenarse y después transferirse a otro cliente distinto en el que comenzar en una misma configuración.
Los contextos pueden a su vez catalogarse y descubrirse, ofreciendo así un nivel de granularidad más amplio que las capas individuales. Pueden crearse diferentes contextos predefinidos y después hacer estos accesibles para facilitar el establecimiento de una determinada configuración en un cliente.
Estándares para metadatos, catálogos y consulta de datos
Los metadatos y las operaciones sobre ellos tienen sus propios estándares bien definidos.
Por una parte, existen estándares dedicados a los metadatos en sí y a la forma de almacenarlos. Estos pueden especificar parámetros relativos a los metadatos tales como los siguientes:
- Contenido de los metadatos, definiendo qué campos son obligatorios y cuáles opcionales.
- Formato de almacenamiento. En general, una descripción del formato a emplear.
- Prácticas adecuadas de creación y actualización. Se definen las pautas correctas que han de seguirse a lo largo del ciclo de vida de los datos.
- Reglas de conformidad. Reglas que permiten comprobar si un determinado metadato se encuentra conforme con el estándar.
Por otro lado, un conjunto de metadatos conforma la base para las consultas sobre un catálogo, el cual describe a su vez un conjunto de datos. Como ya vimos, el catálogo constituye una forma más sencilla y eficaz de consultar los datos, agilizando las operaciones y permitiendo el descubrimiento de datos de forma óptima, por lo que la consulta de estos metadatos también debe estar estandarizada, y debe definirse cómo los clientes deben obtener la información de los metadatos para posteriormente, a partir de dicha información, realizar el acceso a los datos correspondientes que resulten de interés.
ISO 19115 e ISO 19119
ISO 19115 e ISO 19119 son los estándares ISO para metadatos asociados a información geográfica. Definen más de 400 elementos, de los cuales los siguientes forman parte de su núcleo fundamental.
- Título
- Fecha de referencia de los datos
- Idioma
- Categoría en que encuadrar la temática de los datos
- Resumen
- Punto de contacto para los metadatos
- Fecha de los metadatos
- Organismo responsable de los datos
- Localización
- Juego de caracteres de los datos
- Resolución espacial
- Formato de distribución
- Tipo de representación espacial
- Sistema de referencia
- Recurso en línea
- Identificador del fichero de metadatos
- Nombre del estándar de metadatos
- Versión del estándar de metadatos
- Idioma de los metadatos
- Juego de caracteres de los metadatos
En España, existe el Núcleo Español de Metadatos (NEM), un subconjunto de la ISO 19115 definido por un subgrupo de trabajo de la Infraestructura de Datos Espaciales de España (IDEE).
Nomenclátor (Gazetteer)
Un nomenclátor o gazeteer permite la localización de fenómenos geográficos a partir de un determinado nombre. El catálogo sobre el que se basa es una colección de estos fenómenos, cada uno de ellos asociados a un identificador geográfico. Dicho identificador es una referencia espacial en forma de etiqueta o código que identifica un lugar en el mundo real. Ejemplos de tales identificadores son los nombres de ciudades o pueblos (Burgos, Plasencia), los códigos postales (10600), los accidentes geográficos (Puerto de Navacerrada, Pico de la Miel) o las direcciones (Carretera N-V p.k.35, Calle Mayor 32), entre otros. Así, el servicio de nomenclátor permite establecer un sistema de referencia basado en identificadores geográficos.
El servicio recibe como entrada un nombre y utiliza este para localizar los fenómenos geográficos que cumplen un criterio. Este criterio puede ser variable, pudiendo exigir que el nombre coincida plenamente, que comience por él, o que lo contenga, entre otras opciones. Es habitual además que el catálogo contenga una tipología de los fenómenos recogidos (población, río, puerto, lago, etc.), de forma que esta también puede utilizarse para establecer el criterio de consulta (por ejemplo, para localizar todos los ríos que comiencen con la letra «b»).
En el terreno de los nomenclátor encontramos la Norma ISO 19115:2003 ( Geographic Information -- Spatial referencing by Geographic Identifiers ), y los OGC Catalog Services , que permiten estandarizar procesos de consulta como los mencionados.
Estándares para procesamiento
Además de servir datos, pueden servirse procesos sobre esos datos, de tal forma que existan procesos remotos a los que los clientes pueden acceder. También debe estandarizarse la forma de acceso a estos servicios y cómo los clientes efectuarán las peticiones de procesos y la transmisión o definición de los datos que han de tomarse para esos procesos.
Web Processing Service (WPS)
El estándar Web Processing Service (WPS) de OGC está enfocado a definir el marco en el que se ha de producir el servicio de procesos remotos. WPS define una interfaz estándar que facilita la publicación de procesos y su uso posterior por parte de clientes. Se entiende por proceso en este contexto a todo aquel algoritmo, cálculo o modelo que opere sobre datos georreferenciados.
Los procesos que pueden definirse son sumamente flexibles, pudiendo tener un número cualquiera de entradas y salidas, y operar con distintos tipos de datos. Es decir, que ofrece un marco para definir cualquier tipo de proceso de análisis geográfico, tanto si este utiliza datos ráster como si utiliza datos vectoriales. Todos los procesos que hemos visto en la parte correspondiente al análisis espacial pueden ofrecerse como servicios remotos a través de WPS.
Los datos empleados para alimentar los procesos pueden encontrarse en el propio servidor o ser transmitidos a través de la red al igual que la propia petición de proceso por parte del cliente. Asimismo, puede relacionarse este estándar con otros que ya hemos visto, como por ejemplo WFS. Los datos necesarios para ejecutar un proceso que requiera una capa vectorial pueden obtenerse llamando a un servicio WFS, en cuyo caso debe indicarse en los parámetros del proceso los propios parámetros que corresponden a la petición a ese servicio WFS.
Relación entre estándares
Los estándares que hemos visto a lo largo de estás páginas guardan una lógica relación entre ellos. Dentro de un mismo ámbito, los estándares pueden guardar relación con otros similares aun habiendo sido desarrollados por entidades distintas. El objetivo de armonización tecnológica que pretenden los estándares resulta más difícil de lograr si el número de estándares para una misma tecnología es elevado, ya que los fabricantes necesitan dedicar más tiempo y recursos a implementar todos ellos, y lo normal es que opten por implementar solo algunos.
Por este motivo, las organizaciones que promueven estándares trabajan conjuntamente y suelen producir estándares muy similares. En algunos casos, como ya hemos mencionado, algunos estándares OGC son también estándares ISO, existiendo no una similitud sino una absoluta coincidencia.
Más importante es la relación que guardan entre sí estándares dedicados a áreas distintas. Las tecnologías para la gestión y transmisión de datos incluyen diversos elementos que forman un todo interrelacionado. Los estándares correspondientes a esos elementos y a cada proceso particular que se desarrolla deben formar también un todo conectado y poder a su vez «entenderse» con otros estándares relacionados.
Un caso particular de esto es, por ejemplo, el de los estándares WMS, SLD y WFS. El servicio WMS ofrece un mapa, que no es sino una representación de unos datos según unos criterios dados. Esos datos pueden obtenerse de un servicio WFS y los criterios para representarlos pueden expresarse utilizando el estándar SLD. La ventaja de los estándares abiertos, máxime si estos han sido además creados por una misma organización, es la capacidad de interoperar entre ellos, de forma que WMS puede tomar datos de servicios WFS o WCS, o una consulta conforme a Filter Encoding puede aplicarse para consultar un servicio WFS y también un servicio de nomenclátor.
Otro ejemplo en esta línea es el que hemos descrito para un servicio WPS que toma datos de un servicio WFS para operar con ellos.
En su conjunto, deben verse todos los estándares como una gran familia de elementos que armoniza el trabajo con la información geográfica.
Resumen
Hemos visto en este capítulo las ideas fundamentales del binomio cliente-servidor, tanto en su definición más general referente a servicios Web de cualquier tipo, como en aquellos específicos del ámbito SIG. En base a esto, existen distintas formas de llevar a la red tanto los propios datos geográficos como las funcionalidades principales de los SIG de escritorio, y que pueden variar en cuanto a su complejidad, desde simples mapas estáticos hasta aplicaciones Web complejas.
Pese a las elevadas posibilidades que existen hoy en día en cuanto a tecnologías Web, es importante conocer también las limitaciones del entorno de trabajo, las cuales derivan tanto de la propia red como de otros aspectos, por ejemplo el hecho de que la aplicación Web se ejecute dentro de un navegador. Estas limitaciones llevan al desarrollo de técnicas particulares para optimizar el funcionamiento de las aplicaciones SIG Web, entre las que se han de destacar el tiling y el cacheo .
Asimismo, conocemos ya las funcionalidades principales que debe presentar un servidor para responder a las peticiones de un cliente SIG, que son principalmente servir representaciones de los datos geográficos, servir los datos en sí o consultas sobre estos, o bien servir procesos de análisis basados en dichos datos.
Con el fin de garantizar la fluidez en las operaciones dentro del sistema cliente-servidor, aparecen los estándares, los cuales permiten que los elementos de este sistema sean interoperables.