Software y tecnología
El concepto clásico de un SIG es el de una aplicación completa en la cual se implementan herramientas para llevar a cabo las tareas básicas del trabajo con datos geográficos: creación o edición, manejo y análisis. Junto a este enfoque tradicional, con el tiempo han surgido otras formas distintas de aplicaciones que también pueden considerar como parte del ámbito del SIG.
Veremos en este capítulo las características de las aplicaciones SIG, divididas en tres grupos fundamentales: herramientas de escritorio, cartografía en la Web (Web--mapping) y SIG móvil. Asimismo, veremos algunos aspectos tecnológicos relacionados con ellas.
Herramientas de escritorio
Podemos dividir las funciones básicas de un SIG de escritorio en cinco bloques: entrada y salida de datos, visualización, edición, análisis y generación de cartografía. Una aplicación de escritorio habitual presenta todas estas capacidades en cierta medida, aunque no necesariamente con el mismo nivel de implementación.
Entrada y salida de datos
Una aplicación SIG de escritorio debe implementar capacidades para leer datos y, opcionalmente, para guardarlos. Esta ultima es necesaria en el caso en que el SIG pueda generar nuevos datos geográficos (nuevas capas), pero no en aquellas aplicaciones sin capacidades de análisis o edición, donde su empleo no ha de crear nuevos datos.
La existencia de librerías y componentes de acceso a datos en los que las aplicaciones SIG de escritorio pueden apoyarse permite dar soporte al gran número de formatos de datos existentes, mejorando la conectividad entre estas.
Además de acceder a ficheros de datos, en la actualidad es importante poder acceder a bases de datos o servicios remotos. Hablaremos de estos últimos más adelante dentro de este capítulo.
Visualización
La visualización es una función fundamental dentro de los SIG y del trabajo con cartografía en general. Tiene importancia cuando la representación de los datos es el propósito principal de utilizar un SIG, pero también cuando el trabajo está enfocado a la edición o la realización de análisis, ya que la visualización y exploración visual de los datos de partida es un paso previo.
La visualización de datos geográficos en un SIG se compone fundamentalmente de un lienzo sobre el que se sitúan las distintas capas, y que el usuario va conformando añadiendo nuevas capas y editando su simbología, es decir, la forma en la que estas se representan. Las capas se sitúan en un orden dado dentro del lienzo, lo que permite establecer una jerarquía de representación y así lograr el aspecto deseado.
Junto a este lienzo existen herramientas de navegación que permiten ampliar o reducir la escala, o bien modificar el encuadre (Figura 7.1).
El aspecto más destacable de la visualización de datos espaciales en un SIG es que, a diferencia de un mapa clásico donde no pueden modificarse sus características, el usuario puede aquí de forma rápida y sencilla elegir qué ve y cómo lo ve. El dato espacial digital es independiente de la información necesaria para su representación (colores, texturas, etc.), y un mismo dato puede por tanto representarse de maneras diferentes. Esto es particularmente cierto para el caso de capas vectoriales, así como para capas ráster que contengan un valor de tipo no gráfico, es decir, aquellas que no sean imágenes.
Aunque en el caso más habitual la representación de una capa en un lienzo de un SIG es bidimensional, existen también SIG con capacidades de visualización tridimensional. En este caso, las herramientas de navegación son más complejas, existiendo ajustes relativos a la perspectiva, a los ángulos de visión o a la exageración del relieve, entre otros parámetros.
Análisis
El análisis es una capacidad fundamental de los SIG desde sus orígenes. Otros usos, tales como la visualización, pese a ser prácticamente imprescindibles hoy en día, estaban muy limitados en los primeros SIG.
La tendencia actual en los SIG es considerar las capacidades de análisis como herramientas modulares que se ejecutan sobre una plataforma base, la cual comprende las capacidades de visualización y entrada y salida de datos. Todas estas capacidades de análisis son independientes entre sí, aunque pueden coordinarse y emplearse en conjunto para alcanzar un resultado concreto.
Cuando las herramientas de análisis utilizan directamente la base del SIG donde se encuentran las capacidades de visualización y manejo de datos, puede existir cierto grado de interactividad. Por ejemplo, el usuario puede delimitar un área o introducir una coordenada operando sobre el lienzo donde se representan las capas, y este valor se utilizará después como parámetro de entrada para una operación analítica.
En caso de no existir este tipo de interacción entre elementos de análisis y elementos de visualización y exploración de datos, los procesos de análisis suelen constituir utilidades autocontenidas que simplemente toman una serie de datos de entrada, realizan un proceso en el que el usuario no interviene, y finalmente generan un resultado con carácter definitivo. Este resultado podrá ser posteriormente visualizado o utilizado como entrada para un nuevo análisis.
Por su naturaleza, tanto los datos espaciales como los procesos en los que estos intervienen se prestan a formar parte de flujos de trabajo más o menos complejos, y es por ello que en los SIG actuales una funcionalidad básica dentro del análisis es la automatización. Esta se da mediante la creación de tareas complejas que permiten simplificar todo un proceso de muchas etapas en una única que las engloba a todas. La forma anteriormente comentada en que aparecen las formulaciones dentro de un SIG, de forma atomizada y modular, facilita la creación de estos «modelos» a partir de procesos simples.
Asimismo, las herramientas SIG que contienen funcionalidad de análisis suelen permitir el acceso a estas a traves de lenguajes de scripting, lo cual facilita la creación de flujos de trabajo y la automatización de rutinas complejas de análisis. Si bien este trabajo requiere mayores conocimientos, la flexibilidad y potencia que ofrece es mucho mayor.
Edición
Los datos geográficos con los que trabajamos en un SIG no son una realidad estática. La información contenida en una capa es susceptible de ser modificada o corregida, y las funciones que permiten estas tareas son importantes para dotar al SIG de versatilidad. Sin ellas, los datos espaciales pierden gran parte de su utilidad dentro de un SIG, ya que se limitan las posibilidades de trabajo sobre estos. Las funcionalidades de edición son, por tanto, básicas en una herramienta de escritorio.
Las operaciones de edición pueden emplearse para la creación de nueva cartografía, así como para la actualización de esta. Aunque las tareas de edición más habituales son las relacionadas con la edición de geometrías, no es esta la única edición que puede realizarse dentro de un SIG. Podemos distinguir las siguientes formas de edición:
- Edición de geometrías de una capa vectorial.
- Edición de atributos de una capa vectorial, incluyendo la adición o eliminación de atributos en toda una capa.
- Edición de valores de una capa ráster.
Las herramientas destinadas a la edición de entidades geométricas heredan sus características de los programas de diseño asistido por ordenador (CAD), cuya funcionalidad principal es precisamente la edición de elementos gráficos. Aparecen en algunos casos herramientas adicionales, como sucede en el caso de que se registre información topológica.
Generación de cartografía
La mayoría de las herramientas de escritorio incorporan capacidades de creación de cartografía impresa, generando un documento cartográfico que posteriormente puede imprimirse y emplearse como un mapa clásico. Estas capacidades permiten la composición de documentos cartográficos de acuerdo con un diseño dado, y la impresión directa de estas en algún periférico tal como una impresora común o un plotter de gran formato.
Las funciones de diseño que se implementan por regla general en un SIG son similares a las que pueden encontrarse en un software de maquetación genérico, permitiendo la composición gráfica del documento general y el ajuste de los distintos elementos que lo forman. Entre estos elementos, destaca el mapa como tal, es decir, aquel que contiene la representación del dato geográfico.
Junto a esto, las herramientas de escritorio incluyen funcionalidades para automatizar la producción cartográfica, tales como la creación de plantillas o las generación de series de mapas que cubren en su conjunto una amplia extensión, fragmentando esta en unidades (Figura 7.2)
Estas posibilidades surgen de la separación entre los datos espaciales y el diseño del documento cartográfico que los contiene, del mismo modo que ya vimos que existe entre datos y parámetros de representación a la hora de visualizar los primeros.
Cartografía en la Web (Web--mapping). Clientes y servidores
Uno de los avances más importantes en la historia de los SIG lo constituye la llegada del Web Mapping. Entendemos como tal a las tecnologías que permiten incorporar las ideas de los SIG dentro de paginas Web, utilizando un navegador Web como aplicación principal. Asimismo, estas tecnologías, junto a la importancia de Internet, han propiciado el desarrollo de otros elementos tecnológicos tales como servicios de datos remotos, que se utilizan tanto en las aplicaciones de escritorio como en el propio Web Mapping.
Los conceptos de servidor y cliente son fundamentales en este contexto. Veamos algunas ideas generales al respecto.
Conocemos como servidor al elemento encargado de proporcionar (servir) algún tipo de contenido. En el ámbito SIG, se trata fundamentalmente de datos geográficos, que constituyen el principal producto que se distribuye a través de la red dentro de nuestro campo.
El cliente es responsable de pedir ese dato al servidor, tomarlo y trabajar con él. Un navegador Web es un cliente, ya que realiza una petición para mostrar una página Web. Al introducir una dirección Web en la barra de direcciones del navegador, proporcionamos una serie de datos que son los que se emplean para realizar el proceso.
Supongamos la dirección Web:
http://victorolaya.com/writing
Al visitar esa página, se efectúa una petición a través de su dirección, la cual se compone de las siguientes partes:
- http: El protocolo a usar, que define la forma en que se van a comunicar cliente y servidor.
- victorolaya.com: Esta cadena identifica la máquina donde reside la página que buscamos. Es en realidad una versión más legible para el ojo humano de un código numérico que indica la dirección concreta.
- writing: La página que buscamos dentro de todas las que hay en esa máquina.
El proceso mediante el que podemos ver esa página en un navegador Web comprende los cuatro pasos siguientes:
- El cliente realiza la petición.
- La petición se conduce a través de la red hasta el servidor.
- El servidor busca la página y la devuelve a través de la red en caso de encontrarla, o devuelve una pagina de error en caso de no tenerla.
- El cliente recibe la página y la representa.
La figura 7.3 muestra un esquema de este proceso.
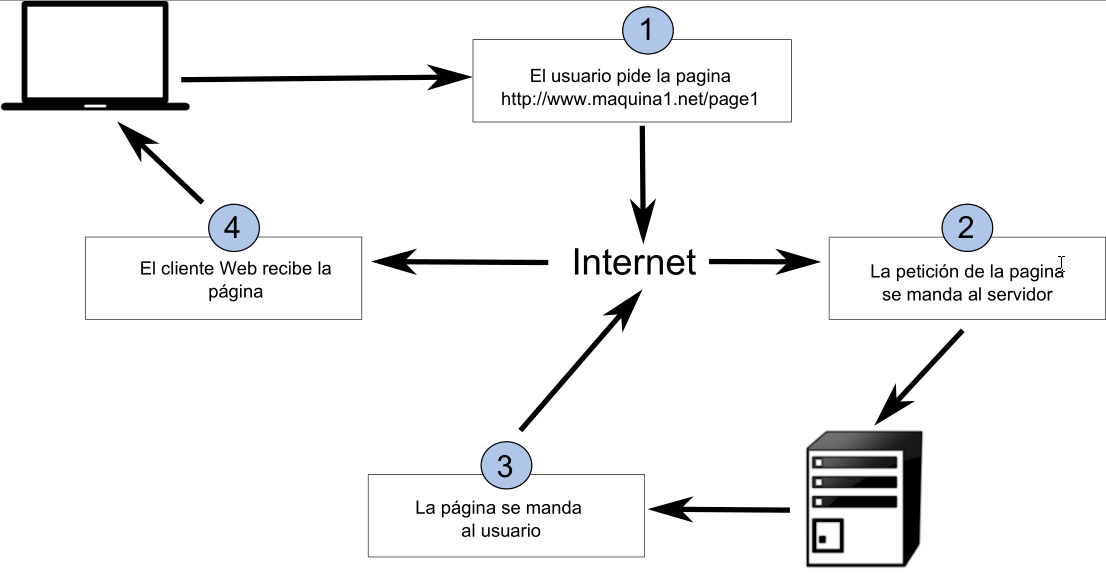
Se establece una relación entre clientes y servidores, en la cual un número variable de clientes se «conectan» a un servidor, del cual obtienen una serie de datos cuando este responde a las peticiones formuladas por cada uno de ellos. En la arquitectura cliente--servidor, este último es el que posee la información a compartir a través de los servicios, mientras que en cada uno de los clientes se almacena tan solo la información personal de estos.
Veamos ahora algunas características de los servidores y clientes dentro del ámbito SIG.
Respecto a los servidores, las capacidades fundamentales en este contexto pueden dividirse en los siguientes grupos:
- Servir representaciones de los datos. El servidor puede responder directamente a este tipo de necesidades, preparando una imagen a partir de los datos geográficos de los que dispone. En el caso de que estos sean ya imágenes —por ejemplo, imágenes de satélite u ortofotos—, bastará servir estas, transmitiendo una versión escalada de las dimensiones exactas que el cliente necesite para representar en pantalla. En caso de que los datos sean de tipo vectorial, o bien ráster sin una forma de representación implícita —por ejemplo, un Modelo Digital del Terreno— es necesario emplear algún método para asignarles dicha representación. Este puede ser asignado por defecto por el servidor, que establecerá una simbología fija, o bien ofrecer un servicio más complejo en el que el cliente no solo pide una representación gráfica de una serie de datos para una zona dada, sino que además puede especificar cómo crear esa representación.
- Servir los datos directamente. Una opción más flexible que lo anterior es que el servidor provea directamente los datos geográficos y sea después el cliente quien los utilice como corresponda, bien sea simplemente representándolos, o bien trabajando con ellos de cualquier otra forma, como por ejemplo analizándolos.
- Servir consultas. Un paso más allá en la funcionalidad que puede ofrecer el servidor es responder a preguntas realizadas por el cliente relativas a los datos, ya sean estas relativas a la parte espacial de dichos datos, o bien a su componente temática. El servidor puede ofrecer como respuesta conjuntos reducidos de los datos de los que dispone, o valores que describan a estos. Estas consultas pueden ser útiles, por ejemplo, para establecer filtros previos cuando se dispone de un conjunto amplio de orígenes de datos. Un cliente Web puede obtener datos de distintos servidores, y puede consultar si, para un zona dada, estos servidores disponen de información, sin más que consultar la extensión cubierta por los datos de cada uno de ellos y comprobar si se interseca con la región de interés. En función de la respuesta, puede o no realizarse posteriormente el acceso a los datos en sí. Como ya vimos, los metadatos son de gran utilidad para conseguir que este tipo de consultas se realicen de forma eficiente.
- Servir procesos. Por último, un servidor puede ofrecer nuevos datos, espaciales o no espaciales, resultantes de algún tipo de proceso o cálculo a partir de datos espaciales. En este caso, el proceso constituye en sí el servicio ofrecido por el servidor, y el cliente debe definir los parámetros de entrada de este y los posibles parámetros de ajuste que resulten necesarios. Los datos con los que se trabaja pueden ser proporcionados por el cliente, incorporándolos a su propia petición, o bien pueden residir en el propio servidor. También pueden emplearse datos en un servidor distinto, a los que el servidor de procesos puede acceder si estos están disponibles, convirtiéndose en cliente de ese segundo servidor (Figura 7.4).
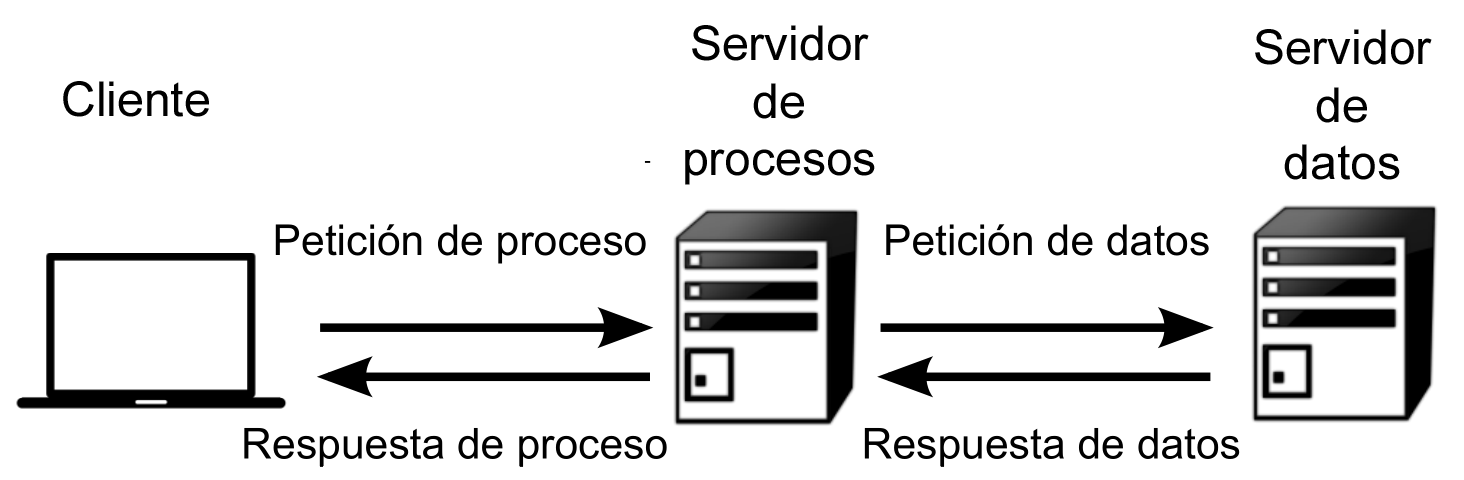
Figura 7.4: Esquema de acceso a un servicio de procesos remotos, el cual a su vez utiliza datos de un segundo servidor. El encadenamiento de procesos permite ampliar notablemente la utilidad de estos.
Respecto a los clientes, distinguimos en función de sus capacidades dos clases:
- Cliente pesado. El cliente pesado es una aplicación individual que no se ejecuta sobre otra aplicación soporte como puede ser un navegador Web. Al ser un programa independiente, debe ocuparse de toda la lógica del proceso y de proveer todas las funcionalidades necesarias, por lo que su tamaño es generalmente mayor.
Los clientes pesados suelen permitir el uso de datos no procedentes del acceso a servicios, tales como datos en ficheros locales, y no están pensados exclusivamente como clientes, sino como aplicaciones más amplias que además disponen de capacidades para aprovechar un determinado tipo de servicios.
En la actualidad, la práctica totalidad de SIG de escritorio son a su vez clientes pesados, ya que pueden consumir servicios tales como los descritos previamente en este apartado.
- Cliente ligero. Se denomina ligero por el tamaño relativamente reducido del programa en sí, lo cual va consecuentemente asociado a unas capacidades limitadas. Hablamos de clientes ligeros cuando nos referimos a Web Mapping y a clientes que se ejecutan sobre un navegador Web, ya que estos suelen ser sencillos en cuanto a sus funcionalidades.
No obstante, los clientes Web empiezan progresivamente a ampliar sus posibilidades, y en ello juegan un importante papel otros servicios distintos a los de mapas o los de datos, como pueden ser los de procesos. Estos permiten que las funcionalidades adicionales no se implementen en el propio cliente (y por tanto sin aumentar en exceso su tamaño y sin disminuir su «ligereza»), sino que sean accedidas también como servicios remotos.
La edición de capas es otra capacidad que puede aparecer en los clientes Web con funcionalidad más avanzada. La evolución de la cartografía Web en esta dirección se dirige desde el Web Mapping al denominado Web GIS, en el que la aplicación Web incluye la totalidad de capacidades clásicas del SIG de escritorio.
Algunas técnicas relacionadas con servicios SIG
Dos técnicas básicas que se emplean actualmente en los clientes que manejan información geográfica son el tiling y el cacheo. Estas técnicas permiten que la experiencia de trabajar con un cliente SIG, ya sea este ligero o pesado, sea más agradable, logrando una mayor fluidez y superando en cierta medida las limitaciones de la red.
Ambas técnicas se utilizan en servicios en los que el servidor provee imágenes, ya que es en estos en los que resultan aplicables, y también donde es más necesario recurrir a este tipo de técnicas.
El tiling es una técnica consistente en dividir las imágenes con las que se trabaja en imágenes menores que formen un mosaico. Esto permite un trabajo más rápido, al utilizar unidades mínimas de menor tamaño y poder reducir la necesidad de transmitir datos a través de la red si se realiza una gestión correcta del conjunto de elementos de ese mosaico. En lugar de transmitir una única imagen se transmiten varias de menor tamaño y la información correspondiente a la posición relativa de estas.
El cacheo, por su parte, es una técnica no exclusiva del ámbito SIG, sino de la Web en general, y consiste en almacenar de forma temporal los datos obtenidos de un servidor en la máquina local. De este modo, si volviera a resultar necesario acceder a esos datos, no han de pedirse al servidor, sino que pueden recuperarse de la copia local, con las ventajas que ello tiene en cuanto a la velocidad de acceso y la fiabilidad del proceso.
El uso conjunto de tiling y cacheo puede disminuir sensiblemente el volumen de datos a transmitir para, por ejemplo, modificar el encuadre de un mapa en una aplicación SIG Web. La figura 7.5 muestra un ejemplo sencillo que servirá para comprender el ahorro de datos que puede conseguirse con el uso conjunto de estas técnicas.
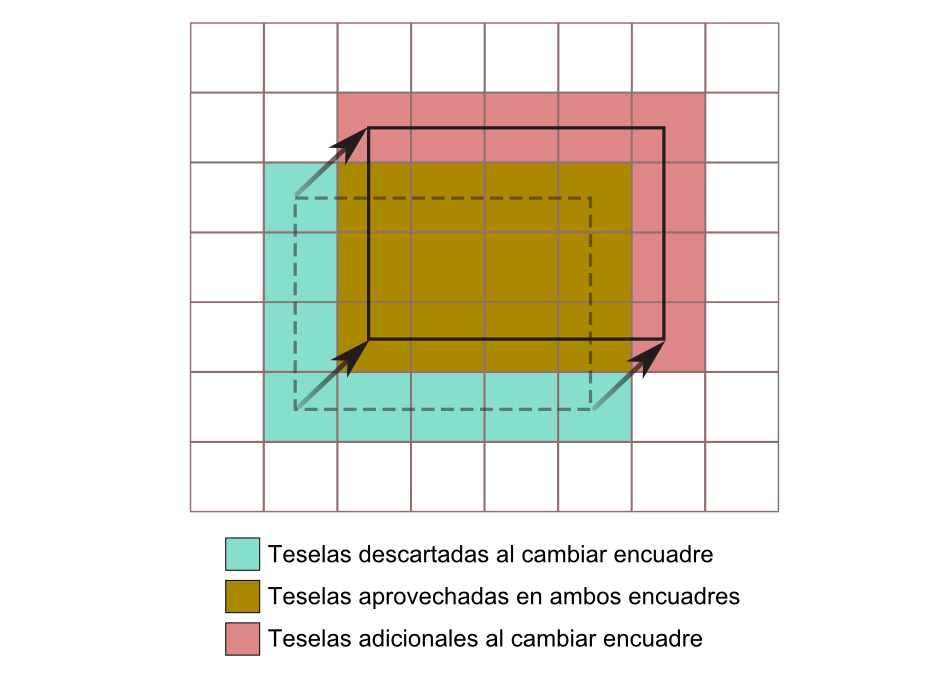
Inicialmente, la aplicación encuadra una región que cubre 20 elementos o teselas. Si el usuario desplaza el encuadre para que cubra otro área distinta, como en el caso mostrado en la figura, el cliente realizará una nueva petición y obtendrá una nueva imagen, que tendrá exactamente el tamaño con que esa imagen va a representarse. Este es exactamente el mismo tamaño que la imagen que encontramos inicialmente en el encuadre original, y por tanto la representación de este encuadre original y posteriormente el encuadre modificado requiere transmitir dos imágenes que cubren cada una de ellas veinte teselas.
Si, por el contrario, aplicamos conjuntamente las técnicas anteriores de tiling y cacheo, al variar el encuadre no es necesario obtener del servidor una imagen que cubra todo el área a representar, sino tan solo los 8 elementos correspondientes a la zona no cubierta por la imagen inicial, ya que los restantes ya habrán sido obtenidos con anterioridad y se encontrarán almacenados (cacheados) en nuestro ordenador. Es decir, el cliente crea la imagen a representar con 8 subimágenes pedidas al servidor y otras 12 ya descargadas previamente, reduciendo sensiblemente el volumen de datos pedidos al servidor.
Una técnica de reciente aparición es la denominada tiling vectorial. Aplicando los mismos principios que el tiling, es decir, la subdivisión de los datos de forma regular, las capas vectoriales se «trocean» en el origen y se envían después solamente los datos necesarios para el área cubierta en el cliente.
Combinando este enfoque con el uso de capas con distinto detalle según la escala, se logran dos ventajas:
- Disminución del volumen de datos.
- Capacidad de modificar la simbología en el cliente.
Al enviar los datos en lugar de una representación de estos, el cliente es quien debe establecer la simbología. Al mismo tiempo, se logran ventajas en la experiencia de usuario, debidas principalmente a la escalabilidad de los datos vectoriales, que permite por ejemplo presentar transiciones más fluidas cuando se modifica la escala del mapa.
Obviamente, este tipo de enfoque es válido unicamente para el caso de capas vectoriales.
Estándares
Para garantizar el buen funcionamiento de un sistema cliente--servidor, es importante definir de forma adecuada cómo se establece la comunicación entre clientes y servidores. Esto obliga a establecer una cierta normalización y crear elementos que sean conocidos e implementados por las distintas partes. Esta lingua franca es lo que denominamos un estándar.
En circunstancias ideales, debe existir una total interoperabilidad con independencia de los formatos y las aplicaciones empleadas, pudiendo interactuar entre sí los distintos clientes y servidores. Los estándares son el elemento que va a permitir esa interoperabilidad, definiendo el marco común que clientes y servidores emplearán para entenderse. Los estándares son los encargados de aportar homogeneidad tecnológica.
La interoperabilidad implica que podemos sustituir unos elementos del sistema en el que se incluyen los clientes y servidores por otros distintos, teniendo la seguridad de que van a interaccionar entre ellos sin dificultades. Las funcionalidades que un cliente o servidor nos ofrece pueden ser distintas a las de otro, pero independientemente de su origen (independientemente del fabricante), si esos elementos implementan un estándar dado, siempre podrán interactuar con todos aquellos que también lo implementen.
Un estándar se considera como tal cuando es empleado por un grupo o comunidad, que lo acepta para la definición de las características de ese producto o servicio en su seno. Si únicamente es el uso del estándar el que lo ratifica como tal, se denomina estándar de facto. Existen estándares que se convierten en normas o estándares de iure, cuando estos son promovidos por algún organismo oficial de normalización o su uso se impone con carácter legal.
Un estándar abierto es aquel cuya definición se encuentra disponible y todo aquel que lo desee puede conocerla y emplearla para el desarrollo de la actividad relacionada con ese estándar.
Los principios fundamentales de los estándares abiertos son los siguientes:
- Disponibilidad. Los estándares abiertos están disponibles para todo el mundo para su lectura y uso en cualquier implementación.
- Máxima posibilidad de elección para los usuarios finales. Los estándares abiertos crean un mercado competitivo y justo, y no bloquean a los usuarios en el entorno de un vendedor particular.
- Gratuidad. Implementar un estándar es gratuito, sin necesidad de pagar, como en el caso de una patente.
- Discriminación. Los estándares abiertos y las organizaciones que los desarrollan no favorecen de ningún modo a uno u otro implementador sobre los restantes.
- Extensión o creación de subconjuntos de un estándar. Los estándares abiertos pueden ser extendidos o bien presentados como subconjuntos del estándar original.
- Prácticas predatorias. Los estándares abiertos pueden tener licencias que requieran a todo aquel que desarrolle una extensión de dicho estándar la publicación de información acerca de esa extensión, y el establecimiento de una licencia dada para todos aquellos que creen, distribuyan y vendan software compatible con ella.
Para tener una noción de lo que en la práctica realmente significa el uso de estándares abiertos en el campo de los SIG, podemos ver la figura 7.6, donde se representa el esquema de una arquitectura no interoperable. Es decir, una arquitectura que no se basa en este tipo de estándares.
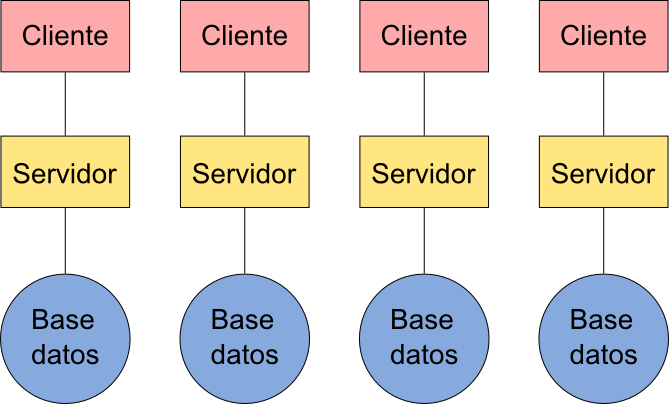
Los datos que se encuentran en cada base de datos son accesibles únicamente a través de un único cliente, que es aquel correspondiente al servidor que ofrece servicios basados en esos datos. Los restantes datos quedan fuera del alcance de ese cliente, ya que no es capaz de acceder a ellos. Las diferentes soluciones cliente--servidor crean en esta situación un conjunto de islas tecnológicas, cada una completamente independiente y sin posibilidad alguna de interactuar con las restantes.
Entre los principales inconvenientes de una arquitectura no interoperable como la representada podemos citar los siguientes:
- Desperdicio de recursos. Cada servicio debe gestionar sus propio conjunto de datos, lo cual requiere abundantes recursos y no es sencillo, además de implicar un elevado coste.
- Necesidad de conocer múltiples clientes. Si para acceder a cada servicio necesitamos su cliente particular, acceder al conjunto de servicios ofrecidos por esos servidores requiere por parte de los usuarios aprender a utilizar tantos clientes como servidores existan.
- Imposibilidad de combinar datos. Dos datos a los que pueda accederse a través de dos servidores distintos no podrán utilizarse simultáneamente en un único cliente, ya que este no podrá comunicarse con ambos servidores.
- Imposibilidad de combinar funcionalidades. Si acceder a los datos a través de un servidor solo se puede hacer empleando un cliente concreto, no existe la posibilidad de aprovechar las funcionalidades de otro cliente sobre esos mismos datos, y el usuario ve así limitadas sus posibilidades de trabajo.
En contraste con lo anterior, tenemos una situación de plena interoperabilidad basada en estándares abiertos como la representada en el esquema de la figura 7.7.
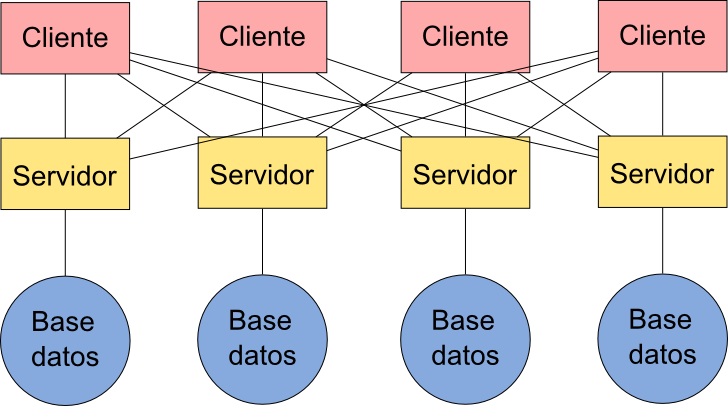
En este caso, existe un servidor que es el que gestiona y ofrece los servicios para cada base de datos, pero a él pueden acceder todos los clientes, ya que por el hecho de estar basados en estándares abiertos es posible una comunicación plena entre dos cualesquiera de ellos.
Principales estándares
Los estándares más habituales en el campo de la información geográfica son elaborados por el Open Geospatial Consortium (OGC). OGC es una organización internacional y voluntaria dedicada a la elaboración de estándares en el ámbito de los contenidos geoespaciales.
Algunos de los estándares OGC más relevantes son los siguientes:
- WMS. Para obtener imágenes de mapas.
- WCS. Para obtener y consultar coberturas (capas ráster).
- WFS. Para obtener y editar entidades geográficas y sus atributos asociados (capas vectoriales).
- WPS. Para servicios de procesos remotos.
- GML. Para almacenamiento de información geográfica.
- CSW. Para consultas en catálogos.
Cada uno de estos estándares está descrito en una especificación, y estas están sujetas a cambios y mejoras, existiendo varias versiones en cada caso.
Junto a estos estándares, encontramos los elaborados por otras organizaciones como ISO o W3C, de ámbito más general, pero que también tienen importancia en el ámbito SIG. Entre ellos, destacar los estándares ISO encargados de definir el formato de almacenamiento de metadatos, o los estándares de W3C para la comunicación en Internet.
SIG móvil
El SIG sobre plataformas móviles (teléfonos, tablets, etc.) tiene una innegable relación con las formas de SIG que hemos visto, tanto el SIG de escritorio como el SIG móvil. A los elementos de estas se suman las propias características de funcionar sobre un dispositivo móvil, que proporcionan un gran número de posibilidades adicionales.
Los dispositivos móviles actuales ofrecen dos funcionalidades fundamentales en este sentido: el acceso inalámbrico a Internet y la capacidad de conocer la posición del dispositivo. Esta última puede introducirse manualmente, calcularse a partir de la red, o bien con métodos basados en el propio dispositivo. A día de hoy, lo más habitual es el uso del sistema GPS, que entra dentro de este ultimo grupo. Una excepción es el caso de posicionamiento en interiores, donde el GPS no está operativo, y en el que pueden emplearse en su lugar métodos basados en una red local dentro del recinto en cuestión.
Las circunstancias anteriores permiten implementar una funcionalidad cercana al SIG clásico, pero con mayor potencial (por ejemplo, para la recogida de datos), así como ofrecer servicios basados en localización.
Algunos de los grupos principales en que estos servicios pueden agruparse son los siguientes:
- Navegación. Cálculo de ruta óptima entre dos puntos, guiado, etc.
- Inventario. Recogida de datos de cualquier tipo sobre el terreno, en los que se almacena la posición asociada al dato en sí.
- Información. Paginas amarillas espaciales o guías de viaje virtuales.
- Publicidad. Anuncios basados en localización, indicación de negocios cercanos, promociones para comercios próximos.
- Seguimiento. Tanto de personas como de productos, a lo largo de rutas predefinidas o no.
- Gestión. Por ejemplo, de infraestructuras, de instalaciones, o de flotas.
La información adicional que el dispositivo móvil provee permite ampliar el contexto de la aplicación SIG, gracias a que se conoce la localización, la orientación (hacia dónde se desplaza el usuario o qué tiene delante de sí), la velocidad, e incluso el entorno físico (iluminación, etc.)