El dato geográfico y su almacenamiento
De todos los subsistemas de un SIG, el correspondiente a los datos es el pilar fundamental que pone en marcha los restantes. Los datos son el combustible que alimenta el SIG. El subsistema de datos es, a su vez, el más interrelacionado, y está conectado de forma inseparable a todos los restantes.
Datos e Información. Tipos de información.
Existe una importante diferencia entre los conceptos de datos e información. Un SIG es un Sistema de Información Geográfica, pero maneja datos geográficos, existiendo diferencias entre estos conceptos.
Entendemos como dato al simple conjunto de valores o elementos que utilizamos para representar algo. Por ejemplo, el código 502132N es un dato.
El dato anterior podemos interpretarlo como si fuera una referencia geográfica, y cuyo significado sería entonces una latitud, en particular 50° 21' 32'' Norte. Si lo interpretamos como un código que hace referencia a un documento de identificación de una persona, la información que nos aporta es en ese caso completamente distinta. El dato sería el mismo, formado por seis dígitos y una letra, pero la información que da es diferente, ya que lo entendemos e interpretamos de manera distinta.
La información es, por tanto, el resultado de un dato y una interpretación, y el trabajo con datos es en muchos casos un proceso enfocado a obtener de estos toda la información posible.
Comprender el significado y las diferencias entre datos e información permiten entender entre otras cosas que la relación entre los volúmenes de ambos no es necesariamente constante. Por ejemplo, los datos 502132NORTE o CINCUENTA VEINTIUNO TREINTAYDOS NORTE tienen un volumen mayor que el dato 502132N, pero recogen la misma información espacial que este (suponiendo que los interpretamos como datos de latitud).
En la información geográfica se distinguen dos componentes: espacial y temática. La componente espacial hace referencia a la posición dentro de un sistema de referencia establecido, y responde a la pregunta ¿dónde?. La componente temática responde a la pregunta ¿qué?, y define la naturaleza del fenómeno que se produce en la localización indicada por la componente espacial.
Mientras que la componente espacial va a ser generalmente un valor numérico, pues son de esa naturaleza los sistemas de coordenadas que permiten expresar una posición concreta en referencia a un marco dado, la componente temática puede ser numérica o alfanumérica (texto). Una variable numérica puede a su vez ser de cuatro tipos: nominal, ordinal, intervalo o razón.
El tipo de variable condiciona las operaciones que pueden realizarse con un dato geográfico en función de cómo sea su componente temática.
Las diferentes formas de representar y almacenar la información, que veremos más adelante en este capitulo, dependen del tipo de variable con que se trabaje.
Un concepto a tener en cuenta en relación con las componentes de la información geográfica es la dimensión. Los elementos que registramos pueden ir desde sencillos puntos (0D) hasta volúmenes tridimensionales (3D) (Figura 5.1).

División de la información. Capas
En un SIG, la información espacial referida a una zona de estudio está dividida en varios niveles, de tal forma que, pese a coincidir sobre un mismo emplazamiento, la información sobre distintas variables se encuentra recogida de forma independiente. Es decir, en función de la componente temática se establecen distintos bloques de datos espaciales. Cada uno de estos bloques temáticos se conoce como capa (Figura 5.2).
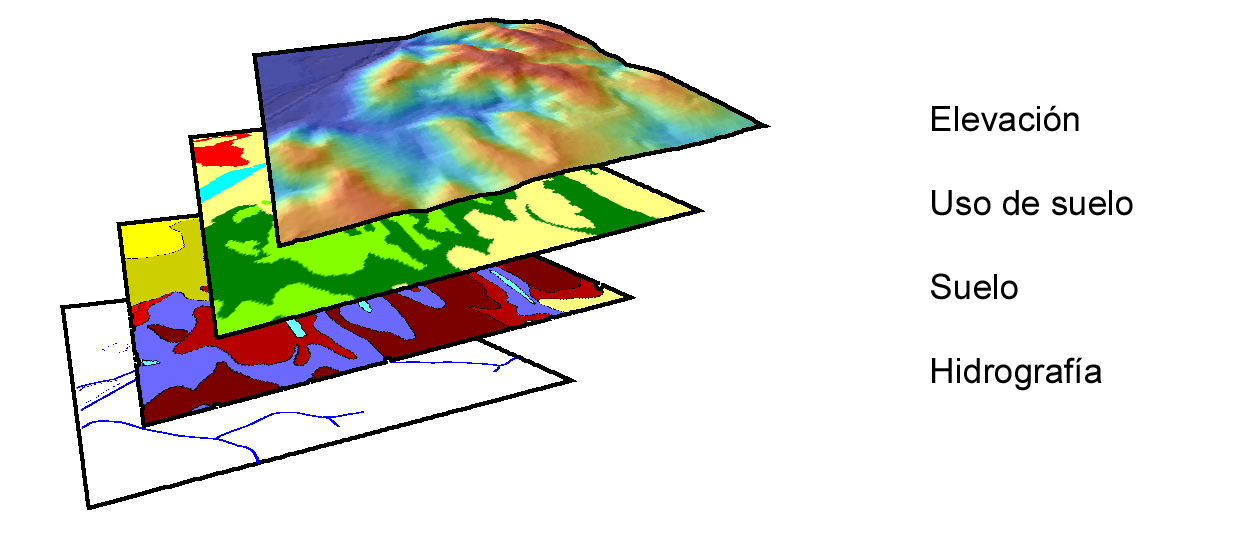
El concepto de capa es imprescindible para comprender todo SIG, y favorece la correcta estructuración de la información y el trabajo con ella. Toda la información geográfica con que trabajemos en un SIG va a ser en forma de capas. Cada una de ellas puede abrirse de forma independiente en un SIG y utilizarse por sí misma o en conjunto con otras.
Con la cartografía clásica, no es posible (o resulta difícil e impreciso) combinar distintos tipos de información, como por ejemplo la contenida en un mapa topográfico y la existente en un mapa de tipos de suelo y otro de vegetación potencial. En el caso de un SIG, los distintos tipos de información se pueden combinar de forma sencilla y limpia, y no aparecen los mismos problemas.
La relevancia del concepto de capa como elemento fundamental de un SIG es enorme, pues constituye el marco básico sobre el que se van a llevar a cabo gran parte de las operaciones. Por ejemplo, vimos en el apartado dedicado a la generalización cartográfica cómo en un SIG podemos utilizar diferentes «versiones» de los datos correspondientes a una zona concreta, y representar una u otra de ellas en función de la escala de trabajo. Estas versiones se almacenarán como distintas capas. La capa es así la unidad fundamental no solo en términos de un área dada, sino también de una escala concreta, y permite una división de los datos óptima a todos los efectos.
La separación de la información en capas evita asimismo la redundancia de datos, ya que cada capa contiene un tipo de información concreto. En un mapa clásico se presentan siempre varias variables, algunas de ellas presentes con carácter general, tales como nombres de ciudades principales o vías más importantes de comunicación. En un SIG, al encontrarse estas variables separadas en sus correspondientes capas, es el usuario quien las combina.
El trabajo con capas permite, por tanto, una estructura más organizada y una mayor atomización de los datos, con las consecuentes ventajas en el almacenamiento, manejo y funcionalidad que esto conlleva.
Además de dividir la información geográfica en capas de acuerdo con su contenido, también dividimos esta con criterios puramente espaciales, «cortándola» en unidades menores que ocupen una región de amplitud más reducida. Este es un procedimiento similar al que encontramos en un mapa impreso, ya que el territorio de un país se encuentra cartografiado en diferentes hojas.
La principal cualidad de un SIG para integrar de forma transparente datos correspondientes a zonas distintas y formar un mosaico único es la separación que existe entre datos y visualización. Los datos son la base de la visualización, pero en un SIG estos elementos conforman partes del sistema bien diferenciadas. Esto quiere decir que los datos se emplean para crear un resultado visual pero en sí mismos no contienen valores relativos a esa visualización.
De este modo, es posible combinar los datos y después representarlos en su conjunto. Un proceso así no puede realizarse con un mapa ya impreso, pues este contiene ya elementos de visualización e incluso componentes cartográficos tales como una flecha indicando el Norte, una leyenda o una escala. Por ello, aunque puedan combinarse, realmente no se «funde» la información de cada uno de los mapas para conformar uno único. En un SIG, por el contrario, la visualización de cuatro o más bloques de datos puede ser idéntica a la que obtendría si todos esos datos constituyeran un único bloque.
Modelos para la información geográfica
El proceso de convertir un área geográfica y la información acerca de ella en un dato susceptible de ser incorporado a un SIG puede dividirse en tres fases:
- Establecimiento de un modelo geográfico. Es decir, un modelo conceptual de la realidad geográfica y su comportamiento.
- Establecimiento de un modelo de representación. Es decir, una forma de recoger el anterior modelo conceptual y sus características propias, reduciéndolo a una serie finita de elementos.
- Establecimiento de un modelo de almacenamiento. Es decir, un esquema de cómo almacenar los distintos elementos del modelo de representación.
Por su mayor importancia, nos centraremos en los modelos de representación. Los modelos de representación que se utilizan principalmente en un SIG son dos: modelo raster y modelo vectorial. Las capas que utilizan estos modelos se conocen como capas raster y capas vectoriales, y esta es la terminología habitual en el ámbito de los SIG para referirse a la naturaleza de una determinada capa.
Modelo ráster
El modelo ráster se basa en una división sistemática del espacio. Todo el espacio queda cubierto y caracterizado como un conjunto de unidades elementales, cada una de ellas con un valor asociado.
Lo más habitual es una división en una malla de celdas cuadradas o rectangulares. Conociendo la orientación de la malla y las dimensiones de cada una de las celdas, así como las coordenadas de al menos una de ellas, es posible conocer las coordenadas del resto en virtud de su estructura regular. Con esto, conocemos los valores de la variable en todos los puntos del espacio cubierto por la capa. El tamaño de celda es un parámetro relacionado con la escala de trabajo de la capa, ya que define la resolución de esta y está en función de la precisión con que se han tomado los datos correspondientes.
La figura 5.3 muestra un ejemplo de una malla ráster.
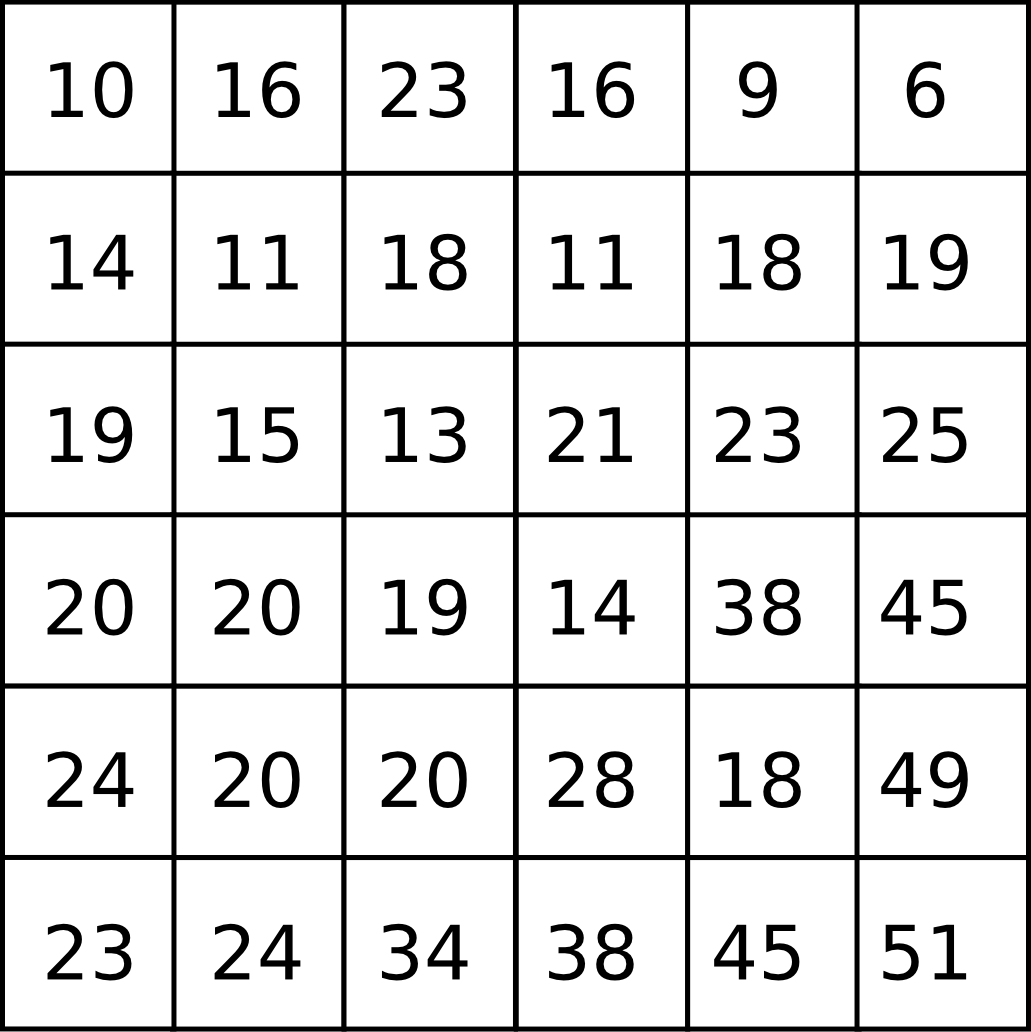
El número de valores distintos recogidos para cada celda coincide con el número de las denominadas bandas. Una banda contiene un único valor en una capa raster. Puede entenderse una capa raster de más de una banda como un conjunto de capas (cada banda sería una subcapa de ese conjunto), teniendo en todas ellas la malla de celdas las mismas características espaciales, y presentandose el conjunto como un único elemento.
El ejemplo más claro de uso del modelo raster lo encontramos en las imágenes. Una imagen digital se compone de una malla de elementos (denominados píxeles, cada uno de los cuales tiene un color asociado). El conjunto de estos píxeles forman la imagen completa. Lo más habitual es que las imágenes contengan 3 bandas, correspondientes a las intensidades de los colores rojo, verde y azul, las cuales al combinarse permiten obtener el color de cada píxel.
Otro uso habitual del modelo raster es en los denominados Modelos Digitales de Elevaciones (MDE), que recogen la topografía de un terreno.
De forma general, los valores de una capa ráster, en cualquiera de sus bandas, son casi exclusivamente numéricos, no estando los SIG preparados para manejar otro tipo de valores en la componente temática de una capa ráster. De esta forma, una capa raster puede equipararse al concepto matemático de una matriz, con las ventajas que ello supone para aplicar sobre ella herramientas matemáticas a la hora de su análisis.
Modelo vectorial
El otro modelo principal de representación es el modelo vectorial. En este modelo, no existen unidades fundamentales que dividen la zona recogida, sino que se recoge la variabilidad y características de esta mediante entidades, para cada una de las cuales dichas características son constantes. Las entidades se componen de primitivas geométricas, y estas pueden ser de tres tipos: puntos, líneas y polígonos (Figura 5.4).
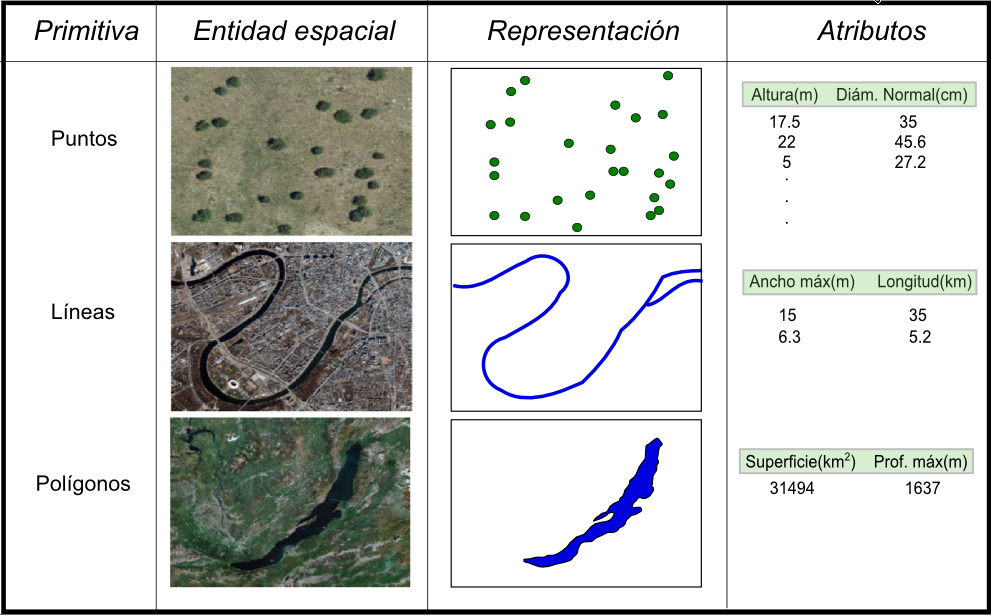
Utilizando puntos, líneas o polígonos, puede modelizarse el espacio geográfico si se asocia a estas geometrías una serie de valores definitorios. Una entidad puede tener varias primitivas. Por ejemplo, en una capa de países, necesitaríamos varios conjuntos para representar España si queremos incluir tanto la peninsula como las islas que la forman. Todos estos polígonos constituyen una única entidad, ya que todos pertenecen al mismo país y tendrán el mismo conjunto de valores asociados.
A la hora de definir las formas geométricas básicas, todas ellas pueden en última instancia reducirse a puntos. Así, las líneas son un conjunto de puntos interconectados en un determinado orden, y los polígonos son líneas cerradas, también expresables por tanto como una serie de puntos. Todo elemento del espacio geográfico queda definido, pues, por una serie de puntos que determinan sus propiedades espaciales y una serie de valores asociados.
Dentro de un SIG, una capa vectorial puede contener un único tipo de primitiva. Así, tenemos capas vectoriales de puntos, de líneas y de polígonos, respectivamente. Una variable puede recogerse con varios tipos de primitivas (por ejemplo, puede indicarse una ciudad con un punto o con un polígono que delimite su perímetro), y la elección de uno u otro tipo de geometría ha de ser función del tipo de fenómeno que se pretende modelizar o la precisión necesaria, entre otros factores.
La componente temática en el modelo vectorial se establece mediante los denominados atributos, que suelen ser múltiples, a diferencia de lo que sucede en el modelo raster, donde lo habitual es tener un único valor para cada celda. Los atributos de una capa vectorial pueden contener información de cualqueir clase, siendo más versátiles que en el caso de las capas ráster, donde ya vimos que se maneja únicamente información numérica. Por su estructura particular (series de atributos asociados a una entidad), la componente temática en el modelo vectorial se presta especialmente a representarse en tablas y almacenarse en una base de datos, y puede analizarse independientemente de la componente espacial.
Un elemento particular del modelo de representación vectorial es la topología. Una capa vectorial contiene topología si en ella se almacenan de algún modo las relaciones espaciales que existen entre sus elementos. Disponer de topología en una capa vectorial es de gran importancia a la hora de llevar a cabo ciertos tipos de análisis, así como procedimientos tales como la edición de los propios datos geográficos.

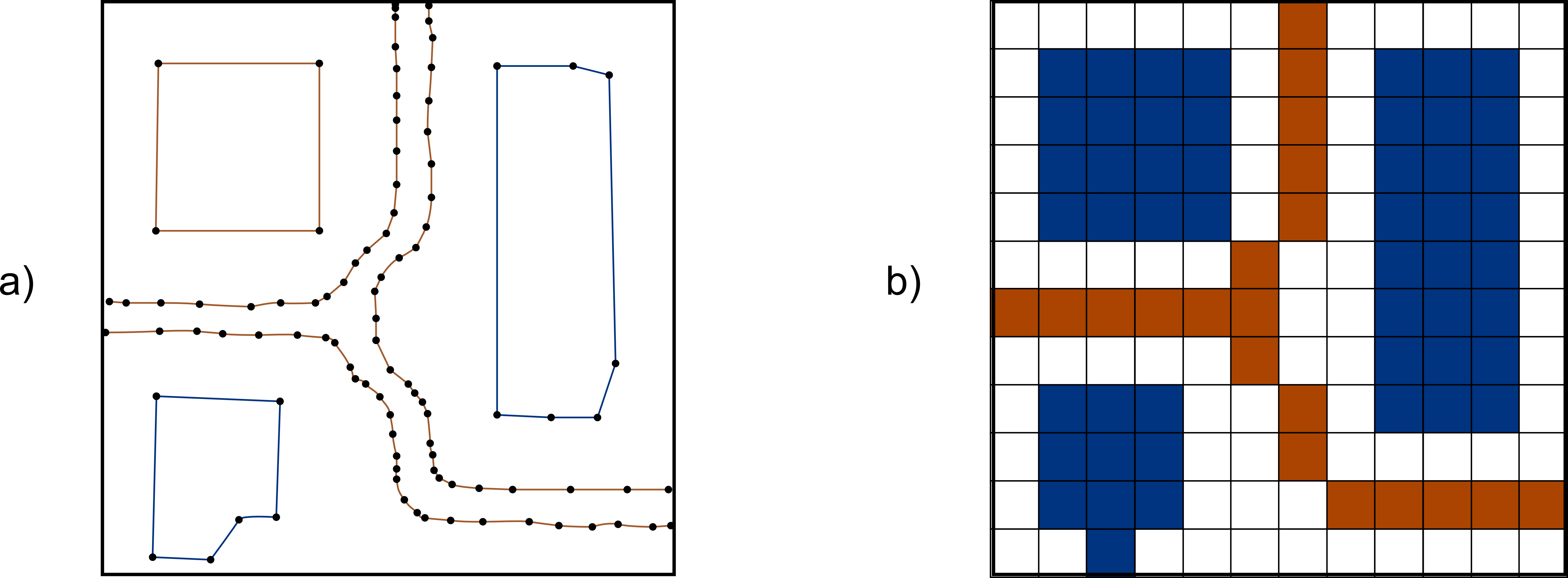
Aunque la mayoría de operaciones con una capa vectorial pueden llevarse a cabo en ausencia de topología, algunas de ellas como el análisis de redes no se pueden llevar a cabo sin topología. Si pensamos en una capa de vías sobre la que desarrollar ese análisis de redes, un mero conjunto de elementos geométricos (líneas en este caso), no nos da información sobre los posibles enlaces entre las vías que quedan representadas. Los puntos donde se cruzan dos vías pueden ser cruces o rotondas (es decir, puede pasarse de una vía a otra, existiendo conexión entre ellas), o bien pasos elevados o subterráneos donde una de las vías pasa por encima de la otra (y por tanto no existe comunicación entre ambas). Las circunstancias son muy distintas en función del tipo de cruce que exista, y por ello es imprescindible conocer esta información para efectuar un análisis de redes correcto (Figura 5.5)
El almacenamiento de entidades basado en una mera lista de coordenadas de cada entidad, sin topología, se conoce popularmente como spaghetti, pues si pensamos en una capa de lineas sin topología que se entrecruzan en el espacio, esta se asemejan en cierta forma a un caótico plato de spaguettis sin orden ni relación entre ellos.
Raster vs vectorial
Tanto el modelo raster como el vectorial pueden emplearse para recoger cualquier tipo de información. La figura 5.6 muestra un ejemplo de esto, representando una capa de vías según ambos modelos. Otro ejemplo para mostrar esto lo encontrarmos en las capas de elevaciones, que ya hemos visto que suelen recogerse en capas raster, en especial si se va a desarrollar sobre ellas algún tipo de análisis. No obstante, pueden recogerse también como una capa vectorial de puntos (este es una caso habitual si se obtienen los datos de un levantamiento topográfico), o bien como una capa de líneas que contenga curvas de nivel, entre otras opciones.
Resulta obvio que las diferencias entre los modelos ráster y vectorial son muy notables, y que cada uno de ellos posee sus propias ventajas e inconvenientes. Algunos aspectos a los cuales puede atenderse para comparar uno y otro modelo son los siguientes:
- Planteamiento. El modelo ráster hace más énfasis en aquella característica del espacio que analizamos (qué y cómo), mientras que el modelo vectorial da prioridad a la localización de dicha característica (dónde)
- Precisión. El modelo ráster tiene su precisión limitada por el tamaño de celda. Las entidades menores que dicho tamaño de celda no pueden recogerse, y la variación espacial que sucede dentro del espacio de la celda tampoco.
Asimismo, existe una imprecisión en las formas. El detalle con el que puede recogerse la forma de una entidad geográfica según el modelo vectorial es, en la práctica, ilimitado, mientras que, como puede verse en la imagen 5.7, el modelo ráster restringe las formas a ángulos rectos, ya que la unidad base es un cuadrado.

Figura 5.7: Imprecisión de forma en el modelo de representación ráster. La división del espacio en unidades cuadradas impide la representación fiel de entidades tales como curvas. - Complejidad. La regularidad y sistematicidad de las mallas ráster hacen sencillo el implementar algoritmos de análisis, muy especialmente aquellos que implican el uso combinado de varias capas. Por el contrario, la irregularidad espacial de las capas vectoriales hace que la implementación de los mismos algoritmos sea sumamente más compleja si se trabaja con estas capas.
No existe un modelo de representación idóneo de forma global, sino que esta idoneidad depende de muchos factores, como por ejemplo:
- Tipo de variable o fenómeno a recoger. Las variables continuas tales como la elevación es más adecuado en general recogerlas en capas raster, para así facilitar su análisis, mientras que las variables discretas es preferible almacenarlas como capas vectoriales.
- Tipo de análisis o tarea a realizar sobre dicha variable. El uso que demos a una capa temática condiciona en gran medida el modelo de datos idóneo. Por ejemplo, en el caso de una capa de elevaciones, su análisis se lleva mejor a cabo si esta información está recogida según el modelo ráster. Sin embargo, si el objetivo principal es la visualización de esa elevación en conjunto con otras variables, unas curvas de nivel pueden resultar más adecuadas, ya que, entre otras cosas, no interfieren tanto con otros elementos a la hora de diseñar un mapa con todas esas variables.
- Contexto de trabajo. Por ejemplo, si queremos trabajar con imágenes, esto nos condiciona al empleo de datos ráster, ya que resulta mucho más sencillo combinarlos con las imágenes, las cuales siempre se presentan como capas ráster.
Existen procedimientos para convertir entre los formatos ráster y vectorial, de forma que el disponer de datos en un modelo de representación particular no implica que debamos desarrollar nuestro trabajo sobre dichos datos directamente, sino que podemos efectuar previamente una conversión.