Bases de datos
Las bases de datos son un elemento fundamental en el entorno informático hoy en día y tienen aplicación en la práctica totalidad de campos. Concebidas con un propósito general, son de utilidad para toda disciplina o área de aplicación en la que exista una necesidad de gestionar datos, tanto más cuanto más voluminosos sean estos. En el ámbito particular de los SIG, los datos son cada día más voluminosos, debido no solo a una mayor cantidad de información, sino también a una mayor precisión en esta, la cual implica un mayor volumen de datos. Además, presentan otra serie de características (uso múltiple, necesidad de acceso eficiente para análisis, necesidad de indexación, etc.), haciendo todas ellas que sea recomendable el uso de bases de datos y tecnologías específicas para su manejo.
Entendemos como Base de Datos un conjunto de datos estructurado y almacenado de forma sistemática con objeto de facilitar su posterior utilización. Los elementos clave de la base de datos son esa estructuración y sistematicidad, pues son responsables de las características que hacen de la base de datos un enfoque superior a la hora de gestionar datos.
Las ventajas de utilizar una base de datos frente a una gestión no organizada de estos las encontramos tanto en los propios datos como en el uso que se hace de ellos. Algunas ventajas que afectan directamente a los datos son las siguientes:
- Mayor independencia. Los datos son independientes de las aplicaciones que los usan, así como de los usuarios.
- Mayor disponibilidad. Se facilita el acceso a los datos desde contextos, aplicaciones y medios distintos, haciéndolos útiles para un mayor número de usuarios.
- Mayor seguridad (protección de los datos). Mayor facilidad de replicación de datos y mejor sincronización.
- Menor redundancia. Con el consiguiente menor volumen de datos y mayor rapidez de acceso.
- Mayor eficiencia en la captura, codificación y entrada de datos.
Esto tiene una consecuencia directa sobre los resultados que se obtienen de la explotación de la base de datos, presentándose al respecto ventajas como, por ejemplo:
- Mayor coherencia. La mayor calidad de los datos que se deriva de su mejor gestión deriva en mayor calidad de los resultados.
- Mayor eficiencia. Facilitando el acceso a los datos y haciendo más sencilla su explotación, la obtención de resultados es más eficiente.
- Mayor valor informativo. Resulta más sencillo extraer la información que los datos contienen, ya que uno de los cometidos de la base de datos es aumentar el valor de estos como fuente de información.
Por último, los usuarios de la base de datos también obtienen ventajas al trabajar con estas, entre los que cabe citar:
- Mayor facilidad y sencillez de acceso. El usuario de la base de datos se debe preocupar únicamente de usar los datos, disponiendo para ello de las herramientas adecuadas y de una estructura solida sobre la que apoyarse.
- Facilidad para reutilización de datos. Esto es, facilidad para compartir.
De forma resumida, puede decirse que la principal bondad de una base de datos es la centralización que supone de todos los datos con los que se trabaja en un contexto determinado, con las consecuencias que ello tiene para una mejor gestión, acceso o estructuración de estos.
Bases de datos relacionales
De entre los distintos modelos existentes para plantear una base de datos, el más habitual, tanto dentro como fuera del ámbito de los SIG, es el de las denominadas bases de datos relacionales. Este modelo utiliza un esquema basado en tablas, que resulta a la vez sencillo de comprender y fácil de utilizar para el análisis y la consulta de los datos. Las tablas contienen un número dado de registros (equivalentes a las filas en la tabla), así como campos (columnas).
La tabla en sí se conoce como relación, ya que recoge la relación existente entre sus elementos, y constituye así el eje central del modelo relacional. Las columnas representan los distintos atributos asociados a la entidad, mientras que las filas conforman los distintos registros. Una fila se forma con un conjunto de n atributos, constituyendo una tupla.
Una base de datos contiene normalmente más de una tabla, ya que suelen ser muchos los tipos de datos a almacenar y resulta conveniente dividirlos en distintas tablas. Además de las relaciones que la tabla en sí implica, es necesario definir interrelaciones entre las distintas tablas, y para ello se emplean los denominados atributos clave. Un atributo clave es aquel que tiene valor único e invariable para cada tupla, pudiendo servir para representar a esta plenamente. Por ejemplo, en una tabla con nombres de personas e información adicional sobre ellas, el número de su DNI puede servir como atributo clave.
Cuando trabajamos con datos espaciales, es habitual emplear la componente espacial como clave, ya que esta suele ser única.
Las interrelaciones entre tablas pueden ser de distintos tipos, según el número de entidades de una tabla con los que se relacionen las entidades de la otra. Tenemos así relaciones de uno a muchos, de uno a uno o de muchos a muchos. Por ejemplo, en una tabla con entidades que representan personas y otra con entidades que representan ciudades, si establecemos una interrelación vive en, se tratará de una interrelación de uno a muchos, ya que en una ciudad pueden habitar varias personas.
Sistemas gestores de bases de datos
Junto con las bases de datos, el elemento fundamental para el aprovechamiento de estas son los Sistemas Gestores de Bases de Datos (SGDB o DBMS, del inglés DataBase Management System). Estos sistemas representan un elemento intermedio entre los propios datos y los programas que van a hacer uso de ellos, facilitando las operaciones a realizar sobre aquellos. Los programas tales como un SIG no acceden directamente a la base de datos, sino que lo hacen a través de un SGBD.
Algunas características que ha de tener un SGBD son las siguientes:
- Acceso transparente a los datos. El SGBD debe crear una abstracción de los datos que haga el trabajo con estos más sencillo, ocultando aspectos internos que no sean relevantes para dicho trabajo. Procedimientos como las consultas se realizan a través del SGBD, que es quien se encarga de interpretar dichas consultas, aplicarlas sobre la base de datos y devolver el resultado correspondiente. El SIG no accede a los datos, sino que se comunica con el SGBD y deja en manos de este el proceso de consulta en sí.
- Protección de los datos. Si la base de datos almacena información sensible, el SGBD debe controlar el acceso a esta, restringiendo el acceso cuando corresponda (por ejemplo, estableciendo distintos permisos de acceso para distintos tipos de usuarios) e implementando los mecanismos de protección necesarios.
- Eficiencia. El SGBD debe ser capaz de gestionar de forma fluida grandes volúmenes de datos o de operaciones (por ejemplo, muchos usuarios accediendo simultáneamente), de modo que dé una respuesta rápida a las peticiones de los usuarios de la base de datos.
- Gestión de transacciones. Las operaciones sobre la base de datos tales como la adición o borrado de un registro se realizan mediante transacciones. El SGBD ha de encargarse de gestionarlas de manera eficiente y segura para que todos los usuarios de la base de datos puedan hacer su trabajo de forma transparente. Se denomina transaccional al SGBD capaz de garantizar la integridad de los datos, no permitiendo que las transacciones puedan quedar en un estado intermedio.
En este sentido, resulta de especial importancia la existencia de lenguajes de consulta, que son los que una aplicación utilizará para comunicarse con el SGBD y expresar las operaciones que desea realizar con los datos de la base de datos. El lenguaje de consulta mas extendido es SQL (Standard Query Language)
Bases de datos espaciales
Todo cuanto hemos visto en los puntos anteriores constituye el conjunto de ideas fundamentales sobre las que se asienta la creación y uso de bases de datos de cualquier índole. La inclusión de datos espaciales en este esquema no es en absoluto obvia, y presenta una complejidad adicional que requiere de nuevos planteamientos. Para que una base de datos pueda considerarse espacial, debe adaptarse y añadir elementos adicionales.
En primer lugar, el dato espacial debe poder almacenarse de forma nativa en la base de datos. Esto quiere decir que una geometría debe poder almacenarse asociada a una entidad en una tabla, del mismo modo que sucede con otros tipos de datos tales como valores numéricos o cadenas de texto. El dato no solo debe poder almacenarse, sino también entenderse por parte del SGBD, para así comprender su naturaleza espacial y poder responder a peticiones relativas a esta por parte del usuario. Esto se denomina almacenamiento transparente, frente al almacenamiento opaco, en el cual la base de datos es capaz de recoger cualquier tipo de valor, pero sin ser capaz de entender su naturaleza y utilizarlo.
Aunque existen planteamientos para almacenar datos ráster en bases de datos, las bases de datos espaciales trabajan principalmente con datos vectoriales y están mejor adaptadas a estos. Las geometrías del dato vectorial se incluyen, como ya se ha dicho, dentro de los valores de un registro de la tabla (que se corresponde con una entidad en el modelo de datos vectoriales). Por su parte, la componente temática del dato espacial puede almacenarse sin problema en la base de datos, sin necesidad de ningún tipo de adaptación.
Cuando la base de datos está preparada para almacenar y trabajar con los datos espaciales, es necesario adaptar el lenguaje de consulta. A las operaciones habituales que un SGBD es capaz de realizar en función de los datos, se añaden otras que utilizan las propiedades espaciales del dato espacial. Se tiene así un lenguaje de consulta espacial, que permite consultas con componente espacial.
Consultas
Entendemos por consulta una operación en la cual preguntamos a los datos geográficos algún tipo de cuestión simple, generalmente basada en conceptos formales sencillos. Este tipo de análisis, aunque no implica el uso de conceptos analíticos complejos, es uno de los elementos clave de los SIG, pues es parte básica del empleo diario de estos.
Aunque las consultas no son algo exclusivo de las bases de datos, es mediante el concurso de estas que adquieren toda su potencia y permite efectuar gran parte de las operaciones habituales de un SIG.
En el contexto espacial, una consulta representa un uso similar al que damos a un mapa clásico, cuando en base a este respondemos a preguntas como ¿qué hay en la localización X? o ¿qué ríos pasan por la provincia Y? No obstante, no debemos olvidar que los datos espaciales tienen dos componentes: una espacial y otra temática. Preguntas como las anteriores hacen referencia a la componente espacial, pero igualmente pueden efectuarse consultas que se apliquen sobre la parte temática. Y más aún, pueden efectuarse consultas conjuntas que interroguen a los datos geográficos acerca de los atributos espaciales y temáticos que estos contienen.
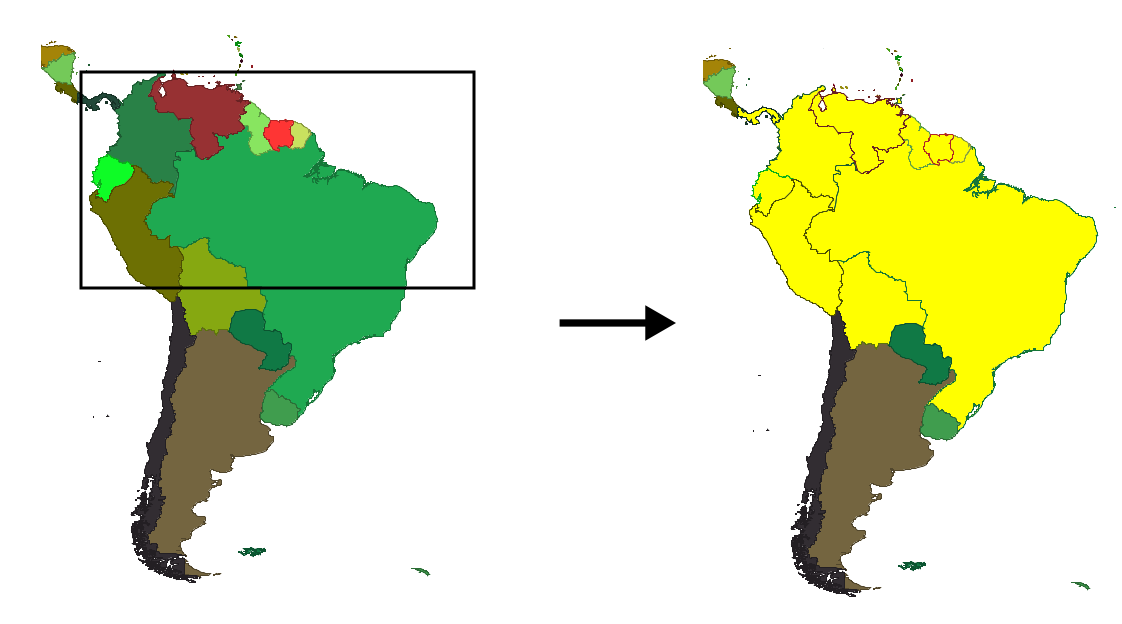
Un ejemplo muy sencillo de consulta es lo que conocemos en un SIG como selección. De todos los registros de la tabla de datos, aquellos que cumplen el criterio indicado se marcan como seleccionados, y posteriormente pueden utilizarse únicamente estos como base de otro análisis, o simplemente el usuario puede ver cuáles han sido los seleccionados para así obtener la respuesta a su consulta. La figura 8.1 muestra un ejemplo típico de esto, en el que el usuario define un área rectangular y se seleccionan las entidades que cumplen la condición de intersecar con él. Los criterios de selección pueden ser sencillos como este, o más elaborados y complejos.
Una consulta nos vale también para extraer información de una base de datos de acuerdo a nuestras necesidades, y para crear posteriormente y a partir de dicha información una nueva capa. Esta operación es útil cuando la base de datos de la que disponemos es muy voluminosa y solo resulta de interés para nuestro trabajo una parte de ella. Puede tratarse de una parte en el sentido espacial (la base de datos contiene datos a nivel mundial y se quiere trabajar a nivel estatal), en el sentido temático (la base de datos contiene mucha información de cada entidad y solo interesan algunos campos), o en una combinación de ambas. Para extraer dicha parte y trabajar únicamente con ella, utilizaremos una consulta.
Veamos algunos ejemplos de consultas. Sea una capa con los distintos países del mundo y una serie de valores económicos y sociales asociados a cada uno de ellos. Consideremos las siguientes preguntas:
- ¿Qué países tienen un Producto Interior Bruto mayor que el de España?
- ¿Qué países han experimentado un crecimiento económico en el último año?
- ¿Cuántos países tienen más de 200 millones de habitantes?
En todos estos casos estamos haciendo referencia a países, los cuales, como sabemos, estarán asociados a elementos geométricos que definan sus propiedades espaciales, es decir, a una componente espacial. Esta componente es la que permite que, además de poder plantear las consultas anteriores, podamos representar cada país en la pantalla y visualizarlo, o saber cuáles de ellos se encuentran en el hemisferio norte (esta sería una consulta espacial, de las que más adelante en este mismo capítulo veremos).
Sin embargo, cuando realizamos consultas como las tres anteriores, no acudimos para nada a la componente espacial. Consultas como estas podrían resolverse si en lugar de una capa dentro de un SIG tuviéramos, por ejemplo, un simple anuario estadístico lleno de tablas con datos correspondientes a cada país.
Las consultas pueden incluir varios criterios en una sola pregunta. Por ejemplo:
- ¿Qué países de la zona euro tienen más de 40 millones de habitantes?
- ¿En qué países de habla inglesa aumentó la población durante el último año?
Para expresar esas consultas se han de incluir elementos de la denominada lógica booleana. Esta implica el uso de operadores lógicos, mediante los cuales se reescribirían las consultas anteriores de la siguiente manera:
- ¿Qué países tienen como moneda el euro y a la vez tienen más de 40 millones de habitantes?
- ¿Que países hablan inglés y sufrieron un aumento de población durante el último año?
Los lenguajes de consulta que se emplean para transmitir estas operaciones a un SGBD permiten el uso de tales operadores para formular consultas.
Si el SGBD es de tipo espacial y entiende que algunas de las columnas de una tabla contiene información espacial (es decir, que cada entidad no solo tiene información temática), pueden plantearse consultas que hacen uso de esta, tales como las siguientes.
- ¿Qué países comparten frontera con Alemania?
- ¿Cuántos países se encuentran completamente en el hemisferio sur?
- ¿Qué países están a menos de 2000 km de España?
Para dar respuesta a esas cuestiones, basta analizar la componente espacial y no necesitamos para nada los datos con los que hemos trabajado anteriormente. Son consultas puramente espaciales. Aunque estas consultas amplían lo que ya conocemos, en realidad no abren ninguna nueva vía de estudio de los datos geográficos. Son consultas a las que podríamos responder utilizando un mero mapa impreso, sin aprovechar el hecho de que dentro de un SIG las componentes espacial y temática se hallan íntimamente vinculadas. La verdadera potencia de las consultas espaciales la encontramos en la combinación de estas consultas sobre la componente espacial y las que vimos anteriormente sobre la componente temática. Así, se pueden plantear, por ejemplo, cuestiones como:
- ¿Qué países del hemisferio norte tiene una densidad de población mayor que la de Perú?
- ¿Cuántos países con más de 10 millones de habitantes se encuentran a menos de 1000 km de la frontera de Rusia?
Estas consultas incorporan elementos que hacen necesario acudir a la tabla de atributos, y otros que requieren analizar la componente espacial, estudiando las relaciones espaciales y topológicas de las geometrías asociadas.
Las consultas pueden incluir varias capas. Por ejemplo, si ademas de la capa de países disponemos de una capa de ríos del mundo, podríamos responder a la pregunta ¿qué países atraviesa el Nilo?
Igualmente, las uniones entre tablas que hemos visto para el caso de la componente temática pueden establecerse mediante un criterio espacial. Se tiene así una unión espacial.
Un ejemplo muy sencillo de unión espacial es el que encontramos si combinamos la capa de países del mundo que venimos utilizando con una capa de ciudades del mundo. Podemos unir a la tabla de esta segunda capa todos los valores que caracterizan al país al que pertenece cada ciudad. Si existe un campo común entre ambas tablas de atributos (por ejemplo, el nombre del país), esto serviría para efectuar esta unión. No obstante, esto no es necesario, ya que existe otro elemento común que no se encuentra almacenado dentro de la tabla, pero que puede tomarse de la componente espacial: toda ciudad debe estar situada dentro de los límites del país al que pertenece. Esto sirve para establecer la relación entre las tablas, y cada ciudad debe relacionarse con aquella entidad dentro de cuya geometría se encuentre el punto que la representa.
Índices espaciales
Si realizamos una consulta a una base de datos, el resultado es un subconjunto de esta con los elementos que cumplen el criterio expresado en la consulta. Si se implementa de forma directa dicha consulta, esta operación implica comprobar todos los elementos de la base de datos y ver cuáles son los que cumplen con el citado criterio. Teniendo en cuenta que una base de datos puede tener un gran tamaño, esta forma de proceder no es la óptima.
Los índices nos permiten alcanzar los elementos que constituyen la respuesta a nuestra consulta, haciéndolo de la forma más rápida y llegando hasta ellos sin tener que pasar por todos los restantes.
Un ejemplo fácil de entender es el de una guía telefónica en la que los nombre están ordenados alfabéticamente. Gracias a ese orden y a que se conoce el alfabeto, se puede buscar rápidamente un nombre sin necesidad de leer todos ellos.
Al utilizar una base de datos, si no disponemos de un índice deberemos recorrer toda ella para dar respuesta a nuestras consultas. No sabemos dónde buscar las respuestas a nuestras consultas, del mismo modo que si no supiéramos que carece de sentido buscar en la letra F el número telefónico del señor Pérez.
Ademas de índices para datos de tipo numérico o texto, en los que resulta obvio establecer un orden natural, en el ámbito de los SIG tienen importancia los denominados índices espaciales. Aunque sus fundamentos teóricos son distintos, el concepto es similar al de índices de bases de datos no espaciales: elementos que permiten optimizar las consultas mediante una correcta estructuración de los datos, en particular en este caso de su componente espacial.
Puede entenderse la idea de un índice espacial mediante un sencillo ejemplo de cómo empleamos ideas parecidas a los índices espaciales de forma natural cuando tratamos de resolver una consulta espacial sin la ayuda de un SIG. Supongamos que tenemos nuestro mapa de países del mundo y queremos averiguar qué países tienen su frontera a menos de 3000 kilómetros de la frontera de España. ¿Cómo operaríamos de manera natural para dar respuesta a esta consulta?
La solución más inmediata es medir la distancia entre España y todos los países restantes, y después tomar aquellos que hayan arrojado un resultado de distancia menor a 3000. La operación daría el resultado esperado, pero implicaría un gran número de mediciones, y no sería una forma óptima de operar. Más probable es que no efectuemos mediciones con los países de América, pues un conocimiento básico de geografía basta para saber que todos ellos se encuentran a más de 3000 kilómetros. No sabemos exactamente a qué distancia se encuentran, pero sabemos que no van a cumplir el criterio establecido en la consulta.
Ese conocimiento básico de geografía que tenemos es en realidad una especie de índice espacial. No sirve para saber las distancias exactas ni resolver la consulta por completo, pero sirve para dar una aproximación y facilitar el trabajo. Descartamos un buen numero de países de forma casi inmediata, y luego solo realizamos las operaciones costosas (la medición) con un subconjunto del total.
De modo similar, los índices espaciales nos permiten obtener resultados en un área concreta sin necesidad de analizar todo el espacio ocupado por el total de los datos. Gracias a ello, hacen las consultas mas efectivas y permiten trabajar con grandes volúmenes de datos.
Los índices espaciales se almacenan junto con los datos a los que hacen referencia, bien en ficheros adicionales o dentro de la propia base de datos, en caso de utilizarse una. Los SGBD espaciales tienen capacidades para calcular estos índices espaciales y almacenarlos en la base de datos, recurriendo a ellos cuando se realiza una consulta que requiera su uso.