\label{Fundamentals}
Fundamentals of cartography and geodesy
Since GIS inherits concepts and ideas previously used to create printed maps, it is mandatory to know them in order to correctly use the tools included in a GIS. The fundamental concepts from cartography and geodesy are the most important ones. Without them, it is not possible to understand GIS.
Basic concepts of geodesy
The main property of georeferenced information is that it has a location, and more particularly, a location on the earth. This location is given with coordinates that define it, which requires a reference system for the coordinates.
Geodesy is the science that provides the theoretical framework for this, and it studies the Earth's shape. Geodesy, through its different branches, provides methods and concepts that allow defining and using precise and rigurous coordinates to locate elements and phenomena that take place on Earth.
Geodesy is needed due to the fact that the Earth is not flat, and when the area that is studied is large enough, the effect of the Earth's curvature cannot be ignored. For this reason, GIS implement the required elements to manage geographical information, taking into account the ideas and principles of geodesy.
One of the main purposes of geodesy is to establish a reference system and define a set of points (known as geodesic vertices), whose position is know with a high level of accuracy. Based on those points, which form a geodesic network, coordinates for any point on the Earth's surface can be computed.
Reference surfaces
To accomplish this, geodesy defines two basic reference surfaces: reference ellipsoid and geoid.
Earth has a spherical shape. However, it is not a perfect sphere, but is instead what is called an ellipsoid. In an ellipsoid, the radius is not constant and depends on the location over its surface. Using an ellipsoid to define the Earth's shape is more precise than assuming it has a spherical shape, and is needed to create accurate cartography, especially when the represented surface is not too large.
The ellipsoid provides a theoretical expression of the Earth's shape, and the next step is to determine the parameters that define it. In the case of a sphere, the only parameter needed is the radius. In the case of an ellipsoid, two parameters have to be determined: the length of semi-major and semi-minor axis.
For historical reasons, many ellipsoids exist, all of them derived from the work of geodesists in different times and places. The first general ellipsoids, which can be used for representing any place on Earth's surface, appeared aproximately a hundred years ago, created as an international reference that can be used for creating cartography in different areas of our planet. The WGS--84 ellipsoid is one of the most popular currently, and it is used by the GPS positioning system.
The other reference surface is the geoid, defined as the three-dimensional surface where every point have the same gravitational attraction. It is an equipotential surface that results from assuming average ocean levels and extending them under the Earth's surface.
As in the case of ellipsoids, there are several geoids as well. These are not constant and evolve to adapt to the changes that take place on the Earth's surface.
Figure 5.1 shows a comparison of the three surfaces: Earth's surface, geoid and ellipsoid.
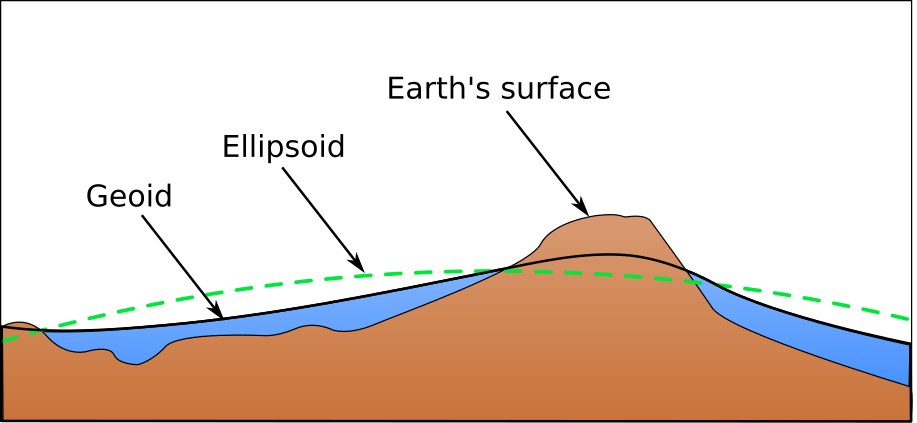
In a general ellipsoid, both the location of it center of gravity and its equatorial plane match those of the Earth. In a local ellipsoid, this does not have to be true, and the ellipsoid by itself is not enough, since we do not know how to place it relative to the real Earth's surface.
The concept of datum solves this problem. A datum is the combination of a reference surface (the ellipsoid) and a point in which it is linked to the geoid. That point is called the fundamental point, and the ellipsoid is tangent to the geoid there. At the fundamental point, a line perpendicular to the geoid is identical to a line perpendicular to the ellipsoid.
Coordinate reference systems
Once we have a model to define the Earth's shape, we can establish a system to code any position over its surface and asign a corresponding coordinate to it. The combination of a coordinate system and a datum is called a coordinate reference system (CRS).
Regarding the coordinate system, we have two main alternatives: using the elements of spherical geometry using the concepts of plane geometry. In the latter, we need a projection system to place the elements on the surface of the ellipsoid into a plane.
Geographical coordinates use a spherical coordinates system in which the location of every point is defined by two angular values: latitude and longitude. Lines of equal latitude are called parallels, while lines of equal longitude are called meridians.
Geographical coordinates are of great utility, especially when working with large regions. However, it is not a cartesian system, and it is difficult to perform tasks such as measuring distances or areas. To simplify operations like those, we need cartesian coordinates. To assign a plane coordinate to every point on te Earth's surface (which is not a plane), we must use a cartographic projection.
Earth's surface is not developable. That is, it cannot be flattened without distortion. For this reason, we need a methodology for converting points on this surface into points on a plane. Figure 5.2 shows this idea.
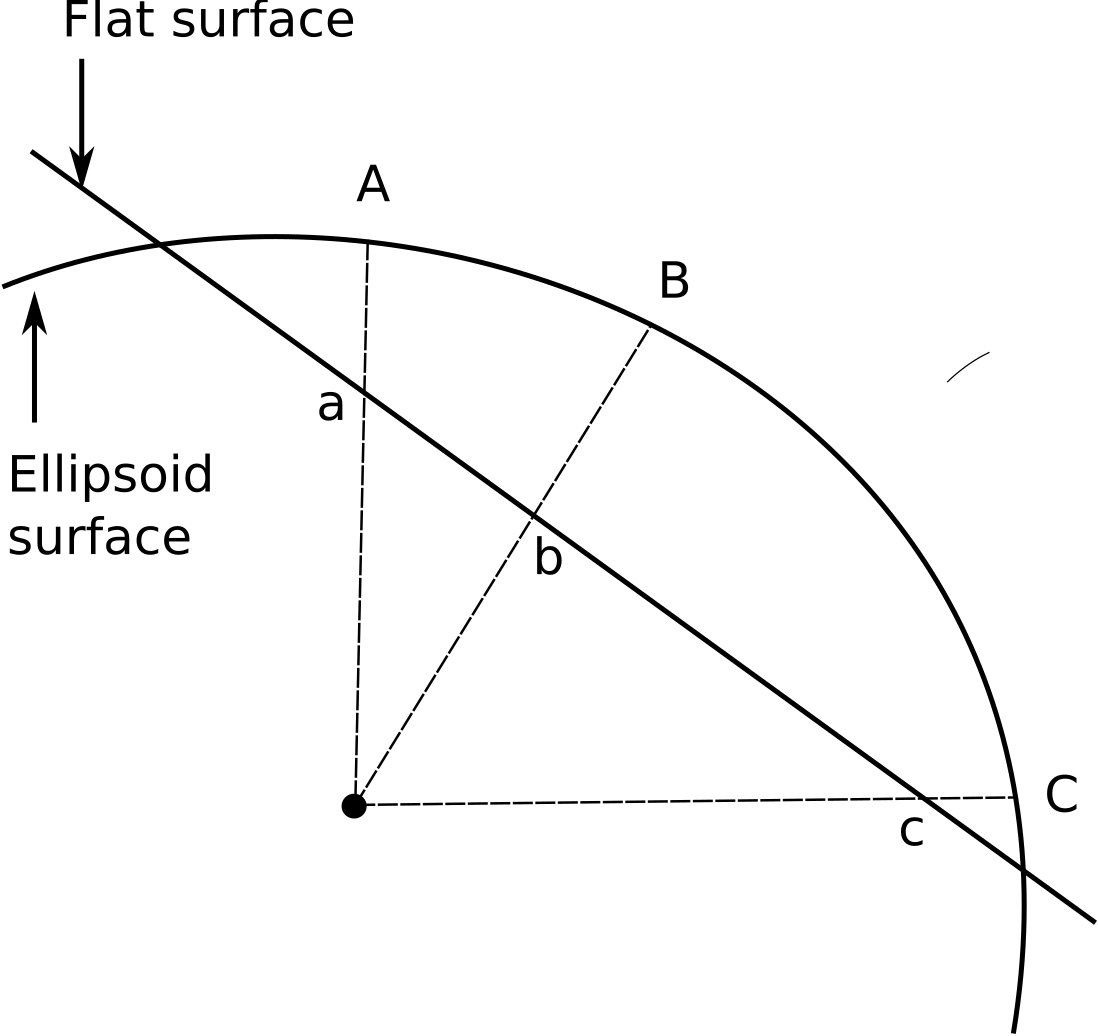
In the case depicted in the figure, point are projected directly onto the plane. Another alternative is to project them onto a surface that, unlike the surface defined by a sphere or an ellipsoid, can be developed (that is, it can be flattened later without distortion). The most usual surfaces for that are the cylinder and the cone. The corresponding projections are called conical projections and cylindrical projections.
It can be seen in the figure that projecting points introduces distortions. For instance, the distance between points A and B is not the same as the distance between points a and b. All projections introduce some sort of distorsion, regardless of their properties. Depending on the metric properties that are preserved undistorted, we have equal-area projections (which preserve area), conformal (preserve angles and shapes) o equidistant (preserve distances).
Depending on the context and the purpose of our data, we might use one or another type of projection.
One of the most widespread projections nowadays is the Universal Transverse Mercator, which is the basis for the UTM coordinate system. This system is not just a projection, but a complete system of many of them. Earth's surface is divided in rectangular regions, and for each of them a different projection and a different set of geodetical parameters are used. It uses a single ellipsoid: WGS-84.
In the UTM system, coordinate are not expressed as absolute coordinates, but instead the are refered to the corresponding rectangle, as relatives coordinates within it.
The UTM grid contains 60 zones, each 6° of longitude in with. Zone 1 is locateed between 180° and 174° West, and numbering increases eastward.
Each zone is segmented into 20 latitude bands, ranging from 80° South to 84° North. These are coded with letters from C to X, excluding I and O due to their similarity to the numerals one and zero. Each band has 8° of latitude in height, except the X band, which has 12.
A UTM rectangle is therefore defined by a number and a letter, and the coordinates that are used to locate a given point on the Earth's surface are referred to the zone to which it belongs. Coordinates are expressed in meters and represent the distance between the point and the origin of the UTM rectangle. The origin is located at the intersection between the meridian passing through the center of the zone and the equator.
To avoid negative numbers, the origin is assumed to have and X coordinate of 500000 meters and a Y coordinate of 10000000 meters, causing all coordinates referred to it to have only positive values.
Coordinate conversion and transformation
It is common when working with GIS to have layers in several different coordinate systems, or in the same coordinate system but using different parameters (such as a different datum). In order to be able to use those layers together, we have to work in a single coordinate systems, and at least some of those layers will have to be converted to it. That is known as coordinate conversion. If the origin and destination coordinate systems have a different datum, coordinate conversion is called coordinate transformation.
In a GIS, conversion and transformation capabilities allow to generate new layers that use a different CRS. Also, GIS include the ability to perform them on-the-fly when layers are rendered, so we can create a map with layers that do not share the same CRS. These are correctly represented on the map and ``match'' one with another, since the GIS is automatically performing the corresponding changes to their coordinates to have them in a common CRS.
To facilitate the use of coordinate reference systems, there are initiatives that organize and code them so each system can be easily identified by a unique code, (called a Spatial Reference System Identifier (SRID)). The most common coding system is the one created by the European Petroleum Survey group (EPSG).
Basic cartographic concepts
Among the fundamental concepts of cartography that any GIS user has to know, scale is the most important one. The scale of a map represent the size ratio between the ``map'' that would be obtained by developing the real surface we are representing (the Earth's surface in this case), and the scale of our smaller map. Knowing this ratio, we can know the real measures of the elements that are included in the map, since we can convert the measurements that we make on it into real-world measures. It's important to keep in mind that these measures are not so ``real'', since the projection might have distorted them, but they are, nonetheless, measures at the original scale of the object that is measured.
Scale is usually expressed as a quotient between the distance measured in a map and the distance that this measure represents in reality. For instance, a 1:50000 scale means that 1 centimeter in a map is equivalent to 50000 centimeters in reality, that is 500 meters. This value is known as the numeric scale.
Regardless of the projection used, scale is completely true only at certain points in the map. In the rest of them, scale changes. The relation between the scale in those points and the numeric scale is known as the scale factor.
Although scale is traditionally understood as a concept related to the data representation, geographical data has an inherent scale not related to its representation, but to the level of detail with which the data was captured on the field. It's more correct to understand scale as something related to the data resolution, that is, related to the minimum mapped size.
The resolution of the human eye is 0.2mm. With that value, and the scale we want to use for a map, we can know the level of detail that we need to use when capturing data to be used as part of that map.
In GIS, as we have seen, data does not contain its visualization. That means we can visualize it at any scale (and that is very easy to do with the zoom tools that are found in most GIS software). However, data has been captured at a given level of detail, However, data has been captured at a given level of detail, which defines the scale meant to be used and represents a limitation of that data. It will not be correct to represent it beyond that scale. In other words, to create a map at a more detailed scale, we will need more detailed data. It's easy to forget that when using a GIS.
Raster layers, as we have seen, have a cell size which defines the resolution of the layer and is related to scale.
Related to the concept of scale, we find the so-called cartographic generalization. It means to express an idea or information in a more succinct manner, so it can be more useful in a given context. In a GIS, generalization is needed to represent data at a smaller (less detailed) scale than its inherent one, mainly because of the limitations imposed by rendering devices. For instance, if we have a layer with the roads of a given country, it makes no sense to use it in a map that represents the whole planet. We will get a mass of lines, and whoever uses that map will not be able to differentiate among them. Also, rendering all those lines will consume a lot of processing power. A much more interesting option would be to just use the main highways and motorways, and to not paint the rest of them. The map will be clearer and more useful, and the screen rendering will be much faster.
Generalization in the context of a GIS also includes other changes that are made to improve the quality of the map and improve the way it conveys information. This might not imply reducing the level of detail, but just altering the data for purely cartographic purposes.
For instance, if we are representing the road layer in a map that covers the entire world, we should not paint the roads at their real size. They would be too thin and almost invisible. We will paint them much thicker, thus creating a map that might be less correct (we are distorting the real size of those roads), but is much more useful.
Generalization is, therefore, a process whose main purpose is to produce a cartographic image more legible and expressive, selecting and adjusting the elements contained in a the map. It emphasizes the important ones, while it omits the least important ones.
Some of the most relevant operations in cartographic generalization are simplification (representing an element that is less complex), aggregation (representing several elements as just one —Figure 5.3—), exaggeration (representing elements with a larger size) and displacement (representing elements at a different location, to ensure legibility).
In GIS, generalization can be implemented as part of the visualization mechanism. That is, when rendering a layer, it is modified at the same time according to the cartographic scale and other factors. This is a time-consuming procedure, and it usually does not yield good results, mainly because of the complexity of the process, which is hard to automate.
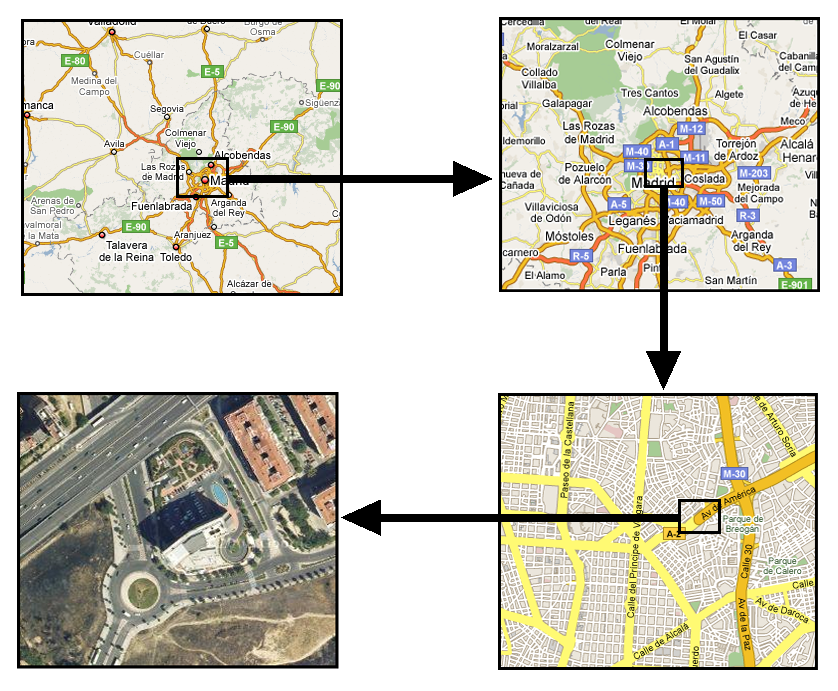
An alternative solution is to use a multi-scale approach (Figure 5.4). Information for a given study area is prepared at different scales (using generalization based on a single one or just using layers with a different origin), and the most convenient one is used in each case depending on the current scale. This is the equivalent of having several printed maps at different scales.
The concept of layer, which we will see in the next chapter, is key for this multi-scale approach.
In the case of images, the approach implies creating so-called pyramids. Instead of using a single image, we have a set of them with different cell sizes. To optimize data handling and minimize the amount of data to be processed when rendering the image, the layer in the pyramid that best fits the current scale is used.