Spatial analysis
Analysis is one of the key capabilities of GIS. Spatial analysis is the quantitative analysis of phenomena, considering the geometric, geographical or topological properties of their elements. Properties such as position, distance and area are relevant when performing spatial analysis.
We perform spatial analysis when we use a classic printed map to search for the highest peak in a given map sheet, read the elevation of a given element such as a city, or plan a touristic activity checking the places to visit and how to move between them using the best roads or following the fastest route. Of course, we can also perform this kind of operations within GIS.
Analysis generates new data, and that data can be in the form of new layers, tables, or simple values.
The result of an analysis might express the same variable as the original data (for instance, computing the average value), or a different one (for instance, if we compute a slope layer from an elevation layer).
Spatial analysis requires spatial data, which can be of a single type, or, instead, of multiple types that are combined. For instance, in the case of finding the highest point in a map, the result is just a coordinate and the only variable used is the elevation. In the case of computing the average elevation of a city, two variables are used: the elevation and the space occupied by the city (defined, for instance, by a polygon with its boundaries). Although all that information is traditionally contained in a single map sheet, in a GIS it will be in two separate layers, both of which will be inputs for this particular analysis.
Analysis in a GIS can help answer questions related to:
- Position or extension.
- Shape or distribution.
- Spatial associations.
- Spatial interactions.
- Spatial variation.
Some examples of spatial analysis
The following sections describe some common types of spatial analysis.
Spatial queries
We already discussed queries in the chapter devoted to databases.
Queries can be combined with other analysis tools for instance, to select a subset of features with which we will later perform some other analysis.
Topological analysis
Queries can be referred not just to the position of geographical elements but also to their relation with other elements. If we have topological information, we can perform analysis that responds to questions such as:
- How can I reach a give coordinate from my current position using the existing road network?
- Which countries share a border with France?
Measurement
Spatial properties can be quantified and measured. Among the most basic ones, we find length, area, perimeter or shape factors. More elaborated ones such as slope or multiple indices derived from basic measurements can also be computed with the help of GIS.
Combination
One of the most typical procedures within GIS is the combination and overlay of layers. The separation of geographical data into layers facilitates this kind of operations and turns GIS into the optimal platform to perform any analysis that requires combining information from different variables.
In the case of vector layers, overlay operations such as union, intersection, difference or clipping are frequently used. Figure 10.1 shows an example of an overlay operation between polygon layers.

Transformations
We include in this group a large set of operations that alter the input data in different ways. Among them we find coordinate transformations, simplification of geometries or the creation of influence areas (buffers). These transformations may affect both the spatial component and the thematic component of the data.
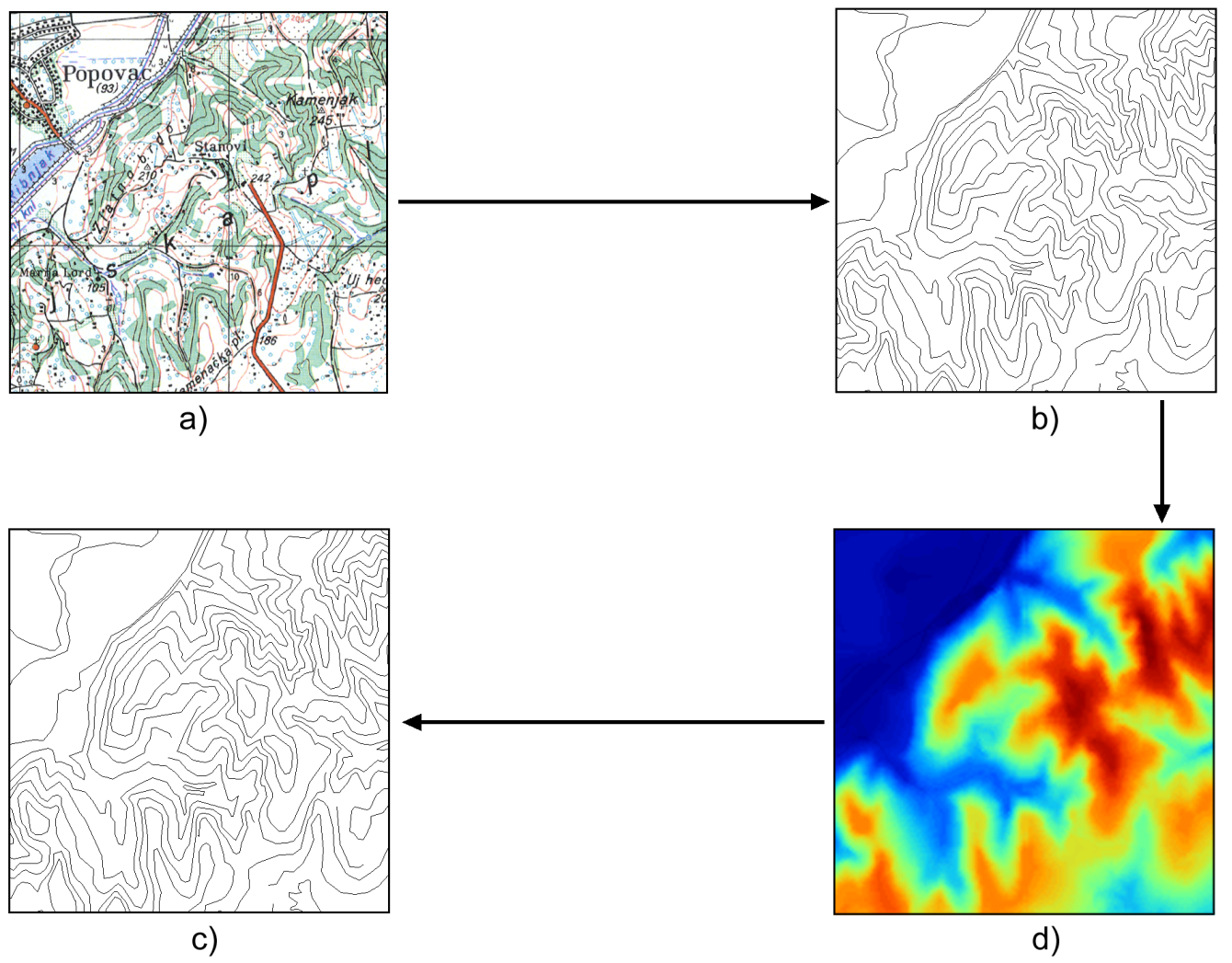
A particular case, already mentioned in a previous chapter, is the conversion between representation models. Figure 10.2 shows an example. Starting with a scanned map (a raster layer) with contour lines, these can be traced and a vector layer created based on them. The lines in that vector layer can be later converted into a raster DEM using interpolation techniques. From the raster DEM it is possible to obtain contour lines at an arbitrary contour distance (of course, within the level of detail of the original data).
Terrain analysis
Terrain analysis is one of the most powerful capabilities we find in GIS. From basic parameters such as slope or aspect, to highly specific morphometric ones, and passing through a large collection of tools for hydrological analysis, a vast array of analysis capabilities is available in this field.
Descriptive statistics
The common elements of classic statistics have their equivalents when working with geographical data, and they allow us to quantitatively describe the data we work with. Here we include centrality and dispersion measures, pattern analysis, and many others. These can be themselves used in hypothesis testing, in case there is a spatial component involved.
These statistical values allow us to respond to questions such as:
- Is average height a constant value across a given country?
- Is there a predominant movement direction for individuals of a given species, or do they move erratically?
Inference
Another important statistical analysis in GIS is the one that helps to infer the behavior of variables and their evolution.
Change modeling is one of the many fields that are rapidly evolving thanks to the help of GIS.
Optimization and decision-making
The layered structure of geographical information in a GIS, which, as we have seen, was ideal for overlay operations, provides also an optimal framework for studying the combined effect of multiple phenomena. GIS is the perfect framework for multiple-criteria analysis.
Questions such as the following ones can be responded to using GIS:
- Which one is the best place to build a new power station considering its effect on the environment and the people living close to it?
- Where should a hospital be located to provide the best possible service to the inhabitants of a given region?
Particularities of spatial data for its analysis
Spatial data have some great potential thanks to their particular properties but at the same time, these properties might limit or condition working with them. In some cases, they might represent problems that have to be considered when analyzing the data; in others, they are just something that anyone working with spatial data should know but that are not problematic per se.
Scale
We can study geographical information at different scales and depending on which one we use, the results obtained will be different. For this reason, apart from considering scale when rendering and visualizing geographical data, the analysis scale should be considered as well when performing any analysis.
The analysis scale should depend on the data properties (accuracy, data type, etc.) and the analysis to be performed with them.
This can be easily understood with the help of figure 10.3. If we want to categorize the form of terrain at a given point, we need to analyze the elevation of the point and also the elevation in its surroundings. Depending on the size of that analysis window around the center point (which is what defines the analysis scale), the results can be very different. In the image, for a small value of the analysis radius, the terrain will be categorized as being a peak. For a larger region, however, it will be considered the bottom of a valley.
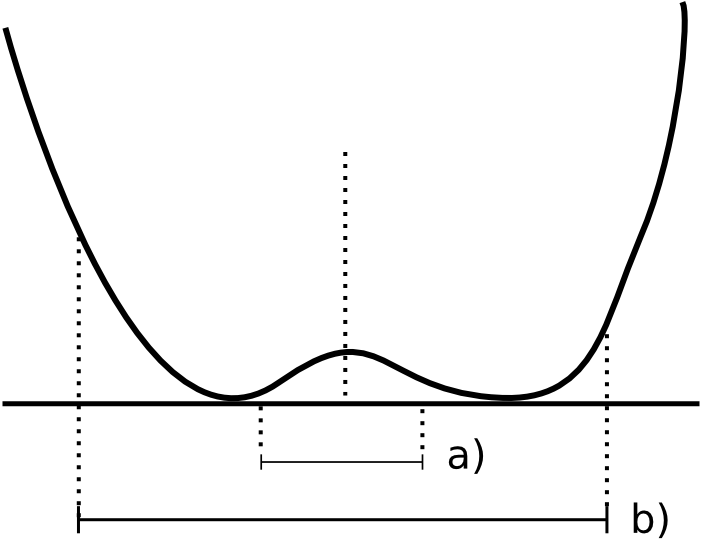
Therefore, we must look at the terrain at the correct distance for which the information that it gives us is the most interesting and correct for the kind of analysis that we are performing. Apart from the fact that there is an optimal analysis scale for each type of analysis, it is also interesting to work at multiple scales, as that will provide us more information than what we can obtain working only at a single scale.
Another example of how the analysis scale affects the analysis result is found in the case of taking measurements. As it can be seen in figure 10.4, the measurement unit (which is implicitly defined by the level of detail of the data) that is used causes the results to be different.
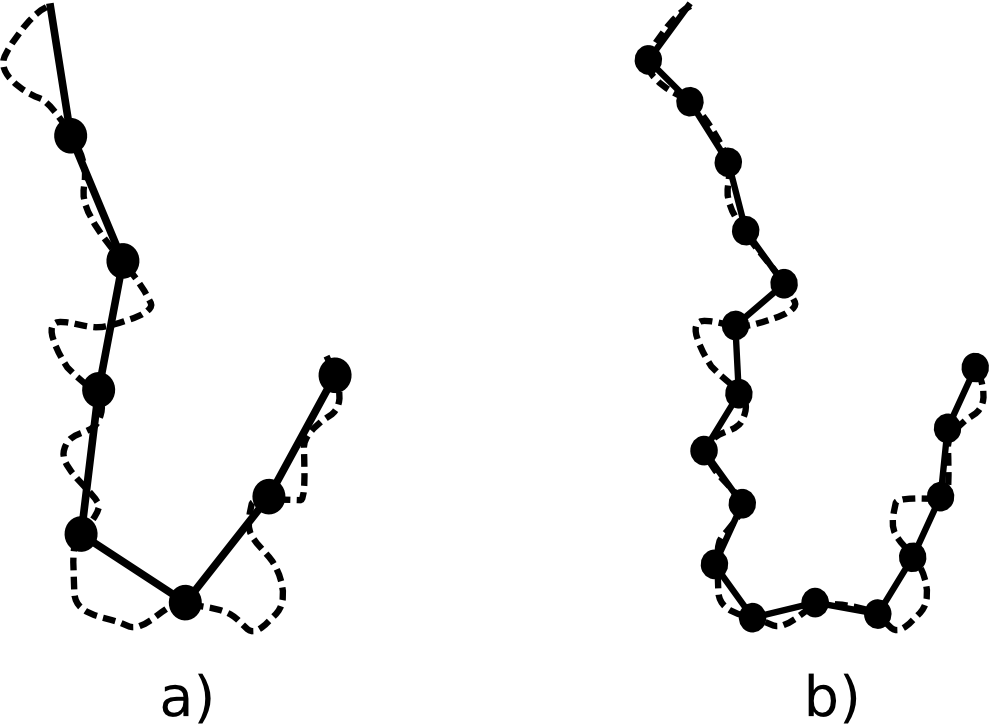
A value by itself might not have meaning if it is not accompanied by the scale that was used to obtain it.
The concept of fractal has a direct link with this.
The Modifiable Areal Unit Problem
Many of the variables with which we work in GIS cannot be measured at a single point, and they must be aggregated for a given area around that point. Examples of that are the percentage of the population within a given age range or the population density.
Areas defined to work with these variables are essentially arbitrary such as countries, counties, districts, etc., and they are defined without taking into account any criteria related to spatial analysis. Using different areas (different units for computing the values of the variable) will yield different results.
This problem is known as the Modifiable Areal Unit Problem (MAUP). Solving or reducing its effect is complex and no solution exists that can be applied in all cases, but whenever we work with this type of geographical data, it is important to keep in mind that there will be a source of statistical bias that cannot be neglected.
Another problem related with the MAUP is the so-called ecological fallacy, which result from (wrongly) assuming that the values computed for a given area can be assigned to the individuals of the population within that area. This would only be true in the case of complete homogeneity.
Spatial autocorrelation
Spatial autocorrelation is the correlation of a variable with itself, in such a way that values of the variable at any point are correlated with values of that same variable in nearby points. For instance, in the case of temperature, points close to a heat source will have a higher temperature that those far from it or closer to a cold spot. If we study the distribution of an infectious disease, reported cases are likely to appear grouped and a large number of them normally cause the nearby populations to also be significantly affected by the disease.
Another way of expressing this is using the well-known Tobler's First Law of Geography, which states that ``everything is related to everything else, but near things are more related than distant things''.
In the above cases, spatial autocorrelation is said to be positive. However, it can be also negative, if higher values are surrounded by lower ones, or there can be no correlation at all, when values in separate points are independent and do not affect each other regardless of distance.
Figure 10.5 shows three raster layers which demonstrate the above types of spatial autocorrelation.

The existence of spatial autocorrelation has several important consequences.
First, many of the most common statistical analyses assume the independence of the variable that is being studied. Since there is a dependency on the spatial component, this component has to be introduced as another variable to consider, in order to ensure that results are sound.
Something similar happens when data have a spatial trend(values of a variable depend on the position; for instance, temperature values, which show a clear trend as latitude changes), since that also invalidates the assumption that data are independent.
If positive correlation exists, statistical inference is less effective. The same number of observations contain less information about the phenomena represented by the variable.
The consequences of spatial autocorrelation, however, are not only negative. If points located in the vicinity of a given one are related to it, and the value of a variable is affected by that proximity, that can be used to estimate values at any point, knowing the values in a set of nearby points. That is the fundamental idea behind interpolation methods.
Structure
Both the data itself and the properties of the phenomenon they represent (such as the aforementioned spatial correlation) have some sort of structure. This structure can have a relevant effect on the analysis results and should be taken into account.
The two basic statistical concepts related to the spatial structure of a process are stationarity and isotropy. Stationarity indicates that the process is translation-invariant. That is, its properties are constant across the whole space and there is no spatial trend. Isotropy means that the process is rotation-invariant, and happens in the same way in all directions.
Border effects
The areas in which we perform spatial analysis have boundaries. These might be artificial, for instance, the limit of the aerial photograph we are working with, or natural. If we study a forest that is close to a lake, the shore will be the limit of the forest. Boundaries distort the result of analysis, specially for those variables that have to be aggregated (density, etc., as we saw for the case of the MAUP)
In some cases, the border effect might manifest itself only for those point close to the border. In others, however, all the points related or somehow connected to the border might be affected, regardless of the distance to it.